第007回_包含関係への対処・条件付字句解析
前回のコラムの終りに述べたように、抽出したトークンに問題があるので検討します。
前回の抽出する過程でも少し触れましたが、抽出したトークン同士に包含関係があります。トークンAの集合とトークンBの集合に包含関係があったり、重なる部分があると、字句解析はAかBのどちらのトークンとして抽出するか決定できません。
ですから、トークンの集合同士は互いに素でなければなりません。
トークン間の包含関係の確認
前回のトークンを再掲すると| WHITE_SPACE ::= (#x20 | #x9 | #xD | #xA)+ |
| WORD ::= (":" | [A−Z] | "_" | [a−z] | [#xC0−#xD6] | [#xD8−#xF6] |
| | [#xF8−#x2FF] | [#x370−#x37D] | [#x37F−#x1FFF] |
| | [#x200C−#x200D] | [#x2070−#x218F] | [#x2C00−#x2FEF] |
| | [#x3001−#xD7FF] | [#xF900−#xFDCF] | [#xFDF0−#xFFFD] |
| | [#x10000−#xEFFFF] | "−" | "." | [0−9] | #xB7 |
| | [#x0300−#x036F] | [#x203F−#x2040] |
| )+ |
| LITERAL ::= '"' '"'以外の文字 '"' | "'" "'"以外の文字 "'" |
| SYMBOL ::= '#FIXED' | '#IMPLIED' | '#PCDATA' | '#REQUIRED' | '%' |
| | '&#' | '&#x' | '&' | '(' | ')' | ')*' | '*' | '+' | ',' | '/>' | ';' | '=' | '<' |
| | '</' | '<?' | '<?xml' | '<![' | '<![CDATA[' | '<!ATTLIST' |
| | '<!DOCTYPE' | '<!ENTITY' | '<!ELEMENT' | '<!NOTATION' | '>' |
| | '?' | '?>' | '[' | ']' | ']]>' | '|' |
| COMMENT ::= '<!−−' 連続した'−−'をもたない文字列 '−−>' |
| CDATA_WORD ::= (Char* − (Char* ']]>' Char*)) |
| CHARDATA_WORD ::= [ˆ<&]* − ([ˆ<&]* ']]>' [ˆ<&]*) |
| IGNORE_WORD ::= Char* − (Char* ('<![' | ']]>') Char*) |
| PI_WORD ::= (Char* − (Char* '?>' Char*) |
■CDATA_WORDとIGNORE_WORDとPI_WORDの包含関係
IGNORE_WORD ::= Char* − (Char* ('<![' | ']]>') Char*)
PI_WORD ::= (Char* − (Char* '?>' Char*)
# IGNORE_WORDはCDATA_WORDの部分集合です。
また、CDATA_WORDとPI_WORDはお互いに差集合部分を含まない限り多くの部分は一致します。
# CDATA_WORDの集合の一部を PI_WORD は含みます。
# PI_WORD の集合の一部を CDATA_WORD は含みます。
#
# 例えば、CDATA_WORDをPI_WORDより優先した字句解析の場合、
# PI_WORDとして取り出すべき字句が']]>'を含まない限り、
# 間違って、CDATA_WORDを取り出します。
CHARDATA_WORD ::= [ˆ<&]* − ([ˆ<&]* ']]>' [ˆ<&]*)
Charと[ˆ<&]には厳密には包含関係はありませんが、CharがXMLファイル内で使える基本的な文字であることを考えると、
[ˆ<&]が示すのは、Char-[ˆ<&]と記述できるので、Char ∋ [ˆ<&]と言うことができ、
CDATA_WORD ∋ CHARDATA_WORDといえます。
WORD
SYMBOL
LITERAL
COMMENT
包含関係から判ること
#プログラム言語では包含関係がなるべく起こらないように先頭の文字については
#厳しい制約が存在しますが、XMLやHTMLはユーザへの制約を
#なるべく除外しているため、上記のような包含関係が発生します。
結局、前回のコラムで抽出したトークン粒度は、
このまま字句解析を行おうとすると、
1. PI_WORD
2. CDATA_WORD
3. PI_WORDまたはCDATA_WORDのどちらにもなりうるトークン
にしか分解できません。
ここで、前述のXML構文を観察すると、3種類のトークンだけで解析可能な構文は1つもないことが判ります。
よって、この字句解析は無意味です。
LITERALトークンの問題
前回も述べましたが、LITERALにも問題があります。| [9] EntityValue ::= '"' ([^%&"] | PEReference | Reference)* '"' |
| | "'" ([^%&'] | PEReference | Reference)* "'" |
| [10] AttValue ::= '"' ([^<&"] | Reference)* '"' |
| | "'" ([^<&'] | Reference)* "'" |
| [11] SystemLiteral ::= ('"' [ˆ"]* '"') | ("'" [ˆ']* "'") |
| [12] PubidLiteral ::= '"' PubidChar* '"' |
| | "'" (PubidChar - "'")* "'" |
| [80] EncodingDecl ::= S 'encoding' |
| ('"' EncName '"' | "'" EncName "'" ) |
EntityValue、AttValueは、LITERALでとれるトークン粒度より小さい、
[ˆ%&"]
[ˆ%&']
[ˆ<&"]
[ˆ<&']
PEReference
Reference
を持つため、正しいトークン粒度でないことが判ります。
また、
[66] CharRef ::= '&#' [0-9]+ ';' | '&#x' [0-9a-fA-F]+ ';'
[67] Reference ::= EntityRef | CharRef
[68] EntityRef ::= '&' Name ';'
[69] PEReference ::= '%' Name ';'
ですから、
[ˆ%&"]、[ˆ%&']、[ˆ<&"]、[ˆ<&']は [0-9]+ [0-9a-fA-F]+ Name
を含み、ここでもトークン粒度に包含関係があります。
包含関係・粒度問題に対する対処・条件付字句解析
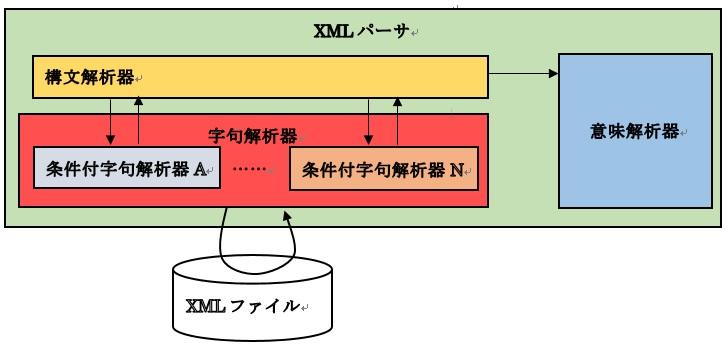
ここまでの検討で全体を一律のトークンだけで字句解析することができないと判りました。そこで、少々複雑になってしまうのを覚悟して、条件付の字句解析を行うことにします。以下ではこれを「条件付字句解析」と呼びます。条件付字句解析の機能は、
・状態に応じて、切り出すトークンの粒度を切り替える
条件付字句解析を使うことで、構文間のトークンの粒度の違い(包含関係)を気にする必要がなくなります。
よって、
全体としてトークン同士に包含関係があっても、
条件の範囲内でトークン同士に包含関係が無ければ、
尚、条件付字句解析は構文解析の指示によって実行するため、次のように関係性が変化します。
EntityValue,AttValue内の構文の整理
EntityValue、AttValue以外の構文はここまでに抽出したトークンの組み合わせで字句解析できます。一方、EntityValue、AttValueの構文は整理する必要があります。
■追加のトークン
NORMAL_TOKEN_A1::=[ˆ<&"]
NORMAL_TOKEN_A2::=[ˆ<&']
NORMAL_TOKEN_B1::=[ˆ%&"]
NORMAL_TOKEN_B2::=[ˆ%&']
と定義します。
構文は、
AttValue ::= '"' (NORMAL_TOKEN_A1 | Reference)* '"'
| "'" (NORMAL_TOKEN_A2 | Reference)* "'"
EntityValue ::= '"' (NORMAL_TOKEN_B1 | PEReference | Reference)* '"'
| "'" (NORMAL_TOKEN_B2 | PEReference | Reference)* "'"
になります。さらに、
AttValue ::= AttValueDoubleQuote | AttValueQuote
AttValueDoubleQuote ::= '"' (NORMAL_TOKEN_A1 | Reference)* '"'
AttValueQuote ::= "'" (NORMAL_TOKEN_A2 | Reference)* "'"
EntityValueDoubleQuote ::= '"' (NORMAL_TOKEN_B1
| PEReference
| Reference)*
'"'
EntityValueQuote ::= "'" (NORMAL_TOKEN_B2
| PEReference
| Reference)*
"'"
とします。
■DoubleQuote、Quoteの切り替えポイントの作成
切り替えポイントを作るために構文を分けます。
AttValue ::= AttValueDoubleQuote | AttValueQuote
AttValueDoubleQuote ::= DoubleQuoteStart AttValueDoubleQuoteSection
DoubleQuoteStart ::= '"'
AttValueDoubleQuoteSection ::= (NORMAL_TOKEN_A1 | Reference)* '"'
AttValueQuote ::= QuoteStart AttValueQuoteSection
Quote ::= "'"
AttValueQuoteSection ::= (NORMAL_TOKEN_A2 | Reference)* "'"
EntityValue ::= EntityValueDoubleQuote | EntityValueQuote
EntityValueDoubleQuote ::= DoubleQuoteStart
EntityValueDoubleQuoteSection
EntityValueDoubleQuoteSection ::= (NORMAL_TOKEN_B1
| PEReference
| Reference)* '"'
EntityValueQuote ::= QuoteStart EntityValueQuoteSection
EntityValueQuoteSection ::= (NORMAL_TOKEN_B2
| PEReference
| Reference)* "'"
NORMAL_TOKEN_A1::=[ˆ<&"]
SYMBOL ('&')
SYMBOL ('&#')
SYMBOL ('&#x')
SYMBOL (';')
SYMBOL ('"')
WORD
# WORD ([0-9]+) WORD ([0-9a-fA-F]+)
# WORD (NAME)の違いは構文解析時のマッチングで処理します。
になります。
NORMAL_TOKEN_A1は条件無しの字句解析器では正しく認識できないため、条件付字句解析の切り替えポイントが必要になります。また、前半で述べたように、NORMAL_TOKEN_A1とWORDは粒度に包含関係があります。
このままでは分解できないかというと、そこは上手に構文が定義されていますので1番目のトークンについてだけ考えればトークンの粒度に包含関係はないようにできています。
つまり、AttValueDoubleQuoteSectionでは、
NORMAL_TOKEN_A1::=[ˆ<&"]
SYMBOL ('&')
SYMBOL ('&#')
SYMBOL ('&#x')
SYMBOL ('"')
をトークンとして抽出し、Reference内でSYMBOL (';')とWORDを抽出すれば良いわけです。
同様に、AttValueQuoteSectionは
NORMAL_TOKEN_A2::=[ˆ<&']
SYMBOL ('&')
SYMBOL ('&#')
SYMBOL ('&#x')
SYMBOL ("'")
をトークンとして抽出します。
EntityValueDoubleQuoteSectionは、
NORMAL_TOKEN_B1::=[ˆ%&"]
SYMBOL ('%')
SYMBOL ('&')
SYMBOL ('&#')
SYMBOL ('&#x')
SYMBOL ('"')
をトークンとして抽出します。
EntityValueQuoteSectionは
NORMAL_TOKEN_B2::=[ˆ%&']
SYMBOL ('%')
SYMBOL ('&')
SYMBOL ('&#')
SYMBOL ('&#x')
SYMBOL ("'")
をトークンとして抽出します。
[67] Reference ::= EntityRef | CharRef
[68] EntityRef ::= '&' Name ';'
[66] CharRef ::= '&#' [0−9]+ ';' | '&#x' [0−9a−fA−F]+ ';'
[69] PEReference ::= '%' Name ';'
の構文は、マッチングするトークンの並びに置き換えると、
Reference ::= EntityRef | CharRef
EntityRef ::= SYMBOL ('&') WORD (NAME) SYMBOL (';')
CharRef ::= SYMBOL ('&#') WORD ([0−9]+) SYMBOL (';')
| SYMBOL ('&#x') WORD ([0−9a−fA−F]+) SYMBOL (';')
PEReference ::= SYMBOL ('%') WORD (Name) SYMBOL (';')
となり、呼び出し側の構文側の条件付字句解析器でSYMBOL ('&'),SYMBOL ('%'),SYMBOL ('&#'),SYMBOL ('&#x')を取り出すことができるので、それらより後ろを別のSectionとして分割すれば良いことが判ります。
よって、
Reference ::= EntityRef | CharRef
EntityRef ::= SYMBOL ('&') EntityRefSection
EntityRefSection ::= WORD (NAME) SYMBOL (';')
CharRef ::= SYMBOL ('&#') CharRefDecimalSection
| SYMBOL ('&#x') CharRefHexSection
CharRefDecimalSection ::= WORD ([0−9]+) SYMBOL (';')
CharRefHexSection ::= WORD ([0−9a−fA−F]+) SYMBOL (';')
PEReference ::= SYMBOL ('%') PEReferenceSection
PEReferenceSection ::= WORD (Name) SYMBOL (';')
と変形し、追加したEntityRefSection、CharRefDecimalSection、CharRefHexSection、PEReferenceSectionのそれぞれを切り替えポイントとします。
EntityRefSection、CharRefDecimalSection、CharRefHexSection、PEReferenceSectionはそれぞれWORDとSYMBOL (';')を抽出すればよいので、特別に字句解析器を用意せずにAttValueに到達する前に使っていた通常の字句解析器で解析できます。
条件付字句解析器ごとのトークンの整理
| No. | 条件 | トークン一覧 |
| 01 | CharDataを構文解析している | CHARDATA_WORD |
| 02 | PITargetの後ろのトークンを構文解析している | PI_WORD |
| 03 | CDataを構文解析している | CDATA_WORD |
| 04 | Ignoreを構文解析している | IGNORE_WORD |
| 05 | DoubleQuoteを構文解析している | SYMBOL ('"') |
| 06 | Quoteを構文解析している | SYMBOL ("'") |
| 07 | AttValueDoubleQuoteSectionを構文解析している | NORMAL_TOKEN_A1, |
| SYMBOL ('&'), | ||
| SYMBOL ('&#') | ||
| SYMBOL ('&#x') | ||
| 08 | AttValueQuoteSectionを構文解析している | NORMAL_TOKEN_A2 |
| SYMBOL ('&'), | ||
| SYMBOL ('&#') | ||
| SYMBOL ('&#x') | ||
| 09 | EntityRefSectionを構文解析している | WORD, SYMBOL (';') |
| 10 | CharRefDecimalSectionを構文解析している | WORD, SYMBOL (';') |
| 11 | CharRefHexSectionを構文解析している | WORD, SYMBOL (';') |
| 12 | EntityValueDoubleQuoteSectionを構文解析している | NORMAL_TOKEN_B1 |
| SYMBOL ('%') | ||
| SYMBOL ('&'), | ||
| SYMBOL ('&#') | ||
| SYMBOL ('&#x') | ||
| 13 | EntityValueQuoteSectionを構文解析している | NORMAL_TOKEN_B2 |
| SYMBOL ('%') | ||
| SYMBOL ('&'), | ||
| SYMBOL ('&#') | ||
| SYMBOL ('&#x') | ||
| 14 | PEReferenceSectionを構文解析している | WORD, SYMBOL (';') |
| 15 | それ以外 | WHITE_SPACE, |
| WORD,SYMBOL, | ||
| LITERAL,COMMENT |
トークンの一覧(修正版)
最後に、今回の検討でトークンが追加になったので修正版を掲載しておきます。WORD ::= (":" | [A−Z]
| [a−z]
| [#xC0−#xD6]
| [#xD8−#xF6]
| [#xF8−#x2FF]
| [#x370−#x37D]
| [#x37F−#x1FFF]
| [#x200C−#x200D]
| [#x2070−#x218F]
| [#x2C00−#x2FEF]
| [#x3001−#xD7FF]
| [#xF900−#xFDCF]
| [#xFDF0−#xFFFD]
| [#x10000−#xEFFFF]
| "−"
| "."
| [0−9]
| #xB7
| [#x0300−#x036F]
| [#x203F−#x2040]
LITERAL ::= '"' '"'以外の文字 '"' | "'" "'"以外の文字 "'"
SYMBOL ::= '#FIXED'
| '#PCDATA'
| '#REQUIRED'
| '%'
| '&#'
| '&#x'
| '&'
| '('
| ')'
| ')*'
| '*'
| '+'
| ','
| '/>'
| ';'
| '='
| '<'
| '</'
| '<?'
| '<?xml'
| '<!['
| '<![CDATA['
| '<!ATTLIST'
| '<!DOCTYPE'
| '<!ENTITY'
| '<!ELEMENT'
| '<!NOTATION'
| '>'
| '?'
| '?>'
| '['
| ']'
| ']]>'
| '|'
COMMENT ::= '<!−−' 連続した'−−'をもたない文字列 '−−>'
CDATA_WORD ::= (Char* − (Char* ']]>' Char*))
CHARDATA_WORD ::= [ˆ<&]* − ([ˆ<&]* ']]>' [ˆ<&]*)
IGNORE_WORD ::= Char* − (Char* ('<![' | ']]>') Char*)
PI_WORD ::= (Char* − (Char* '?>' Char*)
NORMAL_TOKEN_A1::=[ˆ<&"]
NORMAL_TOKEN_A2::=[ˆ<&']
NORMAL_TOKEN_B1::=[ˆ%&"]
NORMAL_TOKEN_B2::=[ˆ%&']