第008回_無条件字句解析
»
これまで設計の話だけでしたが、今回からソースコードも出てきますからより具体的に説明できると思います。
ソースコードの権利関係には気を付けてください。責任を持てません。
全体に対する差集合への対処・無条件字句解析
XMLパーサの字句はトークン粒度に包含関係があるため、条件付字句解析を行うことにしました。しかし、ここまでの検討で無視している問題がまだあります。それは、「トークン粒度を度返しした場合」可能な字句解析があるかどうかです。結論からいうと、「トークン粒度を度返しした場合」可能な字句解析は存在します。それは、以下のXML全体に対する定義の太字部分です。
[1] document ::= ( prolog element Misc* ) − ( Char* RestrictedChar Char* )
この定義が示すことは、XMLのdocumentは1文字以上のRestrictedCharを含むことができない
ということです。
つまり、documentという巨大なトークンを「トークン粒度を度返して」1つ作る場合、字句解析を実行することにより、RestrictedCharを除外して、
document ::= prolog element Misc*
という構文に与えるトークン「DocumentToken」を1つ作ることができます。# ちなみに、これはXML1.0の定義と同じになります
設計は次のように変化します。
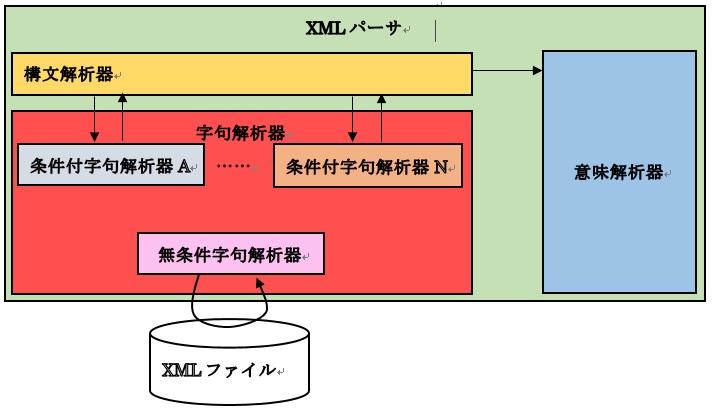
尚、外部参照実体の以下の構文
[78] extParsedEnt ::= ( TextDecl? content ) − ( Char* RestrictedChar Char* )
にも同じ処理ができるのでこちらは、ExtParsedDocumentというクラスを作ります。(実装は必要になるまで後回しとします)Token
字句解析して生成する全てのトークンの親クラスをTokenクラスとします。ファイルパスや位置を示すメンバ変数は、ログクラスに渡すために使います。実装は次のようにします。
public abstract class Token
{
//ファイルパス
protected String m_filePath;
//文字列
protected String m_str;
//開始行
protected int m_startLine;
//開始カーソル位置
protected int m_startCursor;
//終了行
protected int m_endLine;
//終了カーソル位置
protected int m_endCursor;
protected Token()
{
//何もしない
}
public Token(String filePath, String str, int startLine,
int startCursor, int endLine, int endCursor)
{
m_filePath = filePath;
m_str = str;
m_startLine = startLine;
m_startCursor = startCursor;
m_endLine = endLine;
m_endCursor = endCursor;
}
public int length()
{
return m_str.length();
}
public String toString()
{
return m_filePath+":"
+m_startLine+","
+m_startCursor+"-"
+m_endLine+","
+m_endCursor+"|\""
+m_str+"\"";
}
public String getString()
{
return m_str;
}
}
DocumentToken
RestrictedCharを除外したトークンをDocumentTokenとします。実装は次のようになります。
public class DocumentToken extends Token
{
public DocumentToken(String filePath, String str, int startLine, int startCursor, int endLine, int endCursor)
{
super(filePath, str, startLine, startCursor, endLine, endCursor);
}
public String getFilePath()
{
return m_filePath;
}
public String toString()
{
return "[Document]"+super.toString();
}
}
無条件字句解析器(実際は文書トークンのトークナイザ):DocumentTokenizer
実装に際して、必要な機能は以下の3つです。1.DocumentTokenを作成する機能
1-1.ファイルパスを受け取って、指定のファイルを(先頭からEOFまで)読み込む
1-2.読み込んだファイルの文字列にRestrictedCharが含まれるか確認する
1-3.読み込んだ文字列をDocumentTokenに追加する(エラー部分もそのまま追加する)
2.エラーが含まれるかどうか判定する機能
3.エラーメッセージを出力する機能
上記の機能は、基本的には特に悩むこともなく実装できるでしょう。唯一、「1-2のRestrictedCharを含むかどうか」の判定はテクニカルに処理するか検討の余地があります。
何も考えずに処理すると、[2a] RestrictedChar ::= [#x1−#x8] | [#xB−#xC] | [#xE−#x1F]
ということから、次のようになります。
//読み込んだ文字数の数だけ処理する
for(i=0; i<readStr.len; i++)
{
//読み込んだ文字列のi番目の文字を取得する
char c = readStr.charAt(i);
//i番目の文字がRestrictedCharの範囲にある場合
if(
(('u0001'<= c) && (c <='u0008') ) || //条件1
(('u000B'<= c) && (c <='u000C') ) || //条件2
(('u000E'<= c) && (c <='u001F') ) || //条件3
(('u007F'<= c) && (c <='u0084') ) || //条件4
(('u0086'<= c) && (c <='u009F') ) //条件5
)
{
//RestrictedChar!
}
}
最小で、条件1の上限値/下限値の判定をするので比較処理を 2回します。
最大で、条件1から条件5の上限値/下限値の判定をするので比較処理を10回します。
ファイルの文字数をkとした場合、演算回数は
2k<= 演算回数 <=10k
となります。
つまり、最大で文字数*10倍の計算量になります。計算量としてはNオーダーですから問題にしなくても良いのですが、実装がスマートではないのでmapを使って実装してみます。mapで範囲レンジキーを使うには、NavigableMapを使えば実装できます。今回は、putの方法がわかりやすくなるようにNavigableMapをcompositeに持つIntegerRangeKeyMapクラスを作成して実装します。
簡易実装した結果は以下のようになります。
public class IntegerRangeKeyMap<T>
{
//NavigableMapでlowerは表現できるので、
//upperと値を持つ内部クラスを作成する
private class Range
{
private int m_upper;
private T m_value;
public Range(int upper, T value)
{
m_upper = upper;
m_value = value;
}
}
//compositeとしてNavigableMapを持つ
private NavigableMap<Integer, Range> m_map;
//レンジ外の場合に返す値
private T m_outOfRange;
public IntegerRangeKeyMap()
{
m_map = new TreeMap<Integer, Range>();
m_outOfRange = null;
}
//範囲がなく1つだけのkeyの場合のput
public void put(int key, T value)
{
//lowerとupperが同じkeyとして登録する
m_map.put(key, new Range(key, value));
}
//上限、下限を指定するときのput
public void put(int lower, int upper, T value)
{
m_map.put(lower, new Range(upper, value));
}
//キーがRange外のときに返す値を指定する
public void setOutOfRange(T outOfRange)
{
m_outOfRange = outOfRange;
}
public T get(int key)
{
T retval = null;
//keyにlowerがもっとも近いentryを取得する
Map.Entry<Integer,Range> entry = m_map.floorEntry(key);
//全てのputした指定キー範囲より小さいkeyを指定した場合
if (entry == null)
{
retval = m_outOfRange;
}
//全てのputの指定キー範囲のいずれかより大きいkeyを指定した場合
else
{
//もっとも近いentryの値を取得する
Range r = entry.getValue();
//もっとも近いentryの値の上限境界以下の場合
//つまり範囲内の場合
if (key <= r.m_upper)
{
retval = r.m_value;
}
//もっとも近いentryの値の上限境界より大きい場合
//つまり範囲外(指定した範囲と範囲の狭間の何にも当たらない値)の場合
else
{
retval = m_outOfRange;
}
}
return retval;
}
}
public class RestrictedCharMap
{
//intの範囲をkeyに指定できるマップ
// value値はBooleanを返す
private IntegerRangeKeyMap<Boolean> m_map;
//コンストラクタ
public RestrictedCharMap()
{
//Documentは
// [2a] RestrictedChar ::= [#x1-#x8]
// | [#xB-#xC]
// | [#xE-#x1F]
// | [#x7F-#x84]
// | [#x86-#x9F]
//を除外するので以下のmapを作成する
m_map = new IntegerRangeKeyMap<Boolean>();
//mapの登録
m_map.put('\u0001', '\u0008', Boolean.TRUE);
m_map.put('\u000B', '\u000C', Boolean.TRUE);
m_map.put('\u000E', '\u001F', Boolean.TRUE);
m_map.put('\u007F', '\u0084', Boolean.TRUE);
m_map.put('\u0086', '\u009F', Boolean.TRUE);
m_map.setOutOfRange(Boolean.FALSE);
}
private boolean containsRestrictChar(String str)
{
//戻り値
boolean retval = false;
//カーソル
int cursor = 0;
//文字列長
int len = str.length();
//文字列終端まで処理する
while(cursor < len)
{
//cursor文字目の文字を取得する
char c = str.charAt(cursor);
//mapに問い合わせてRestrictedCharか判定する
retval |= m_map.get(c);
//次の文字へ
cursor++;
}
return retval;
}
}
public class DocumentTokenizer
{
static private final String ms_errorMessage
= "cause:can't contain RestrictedChar [%c]";
private RestrictedCharMap m_map;
private BufferedReader m_br;
private DocumentToken m_token;
private int m_lineNum;
//RestrictedCharの有無
private boolean m_hasRestrictedChar;
private String m_errorMessage;
private String m_filePath;
public DocumentTokenizer(String path, BufferedReader br)
{
m_map = new RestrictedCharMap();
m_br = br;
m_token = null;
m_lineNum = 0;
m_hasRestrictedChar = false;
m_errorMessage = "";
m_filePath = path;
}
//トークン化する
public void tokenize()
{
String buffer="";
int lastCursor=-1;
//無限ループ
while(true)
{
try
{
//1行読み込む
String str = m_br.readLine();
//EOFに到達している場合
if (str == null)
{
break;
}
//EOFに到達していない場合
else
{
//読み込み行数を加算する(初期値0なので1行目から加算してOK)
m_lineNum++;
//文字列を追加する
buffer+=str;
//行文字列にRestrictedCharが入っていないかチェックする
m_hasRestrictedChar |= containsRestrictChar(str);
//改行文字が抜けてしまうので追加する
buffer+="\n";
lastCursor = str.length();
}
}
catch (IOException e)
{
// TODO 致命的エラー用の処理は今後実装する
}
}
//Fileに対してXML Documentトークンを一つ作成する
m_token = makeToken(m_filePath, buffer, 0,0,m_lineNum,lastCursor);
}
private boolean containsRestrictChar(String str)
{
//戻り値
boolean retval = false;
//カーソル
int cursor = 0;
boolean containsRestrictChar = m_map.containsRestrictChar(str);
//RestrictedCharの場合
if (containsRestrictChar)
{
String message = String.format(ms_errorMessage, str);
//errorメッセージに追加する
m_errorMessage = m_lineNum+":"+cursor+"|"+message;
//戻り値をtrueにする
retval = true;
}
//RestrictedCharでない場合
else
{
//何もしない
}
return retval;
}
public void putMessageIfError()
{
//RestrictedCharを持っている場合
if (m_hasRestrictedChar)
{
System.out.println(m_errorMessage);
}
//RestrictedCharを持っていない場合
else
{
//何もしない
}
}
public DocumentToken getToken()
{
return m_token;
}
public boolean hasError()
{
return m_hasRestrictedChar;
}
private DocumentToken makeToken(String filePath, String str, int startLine,
int startCursor, int endLine, int endCursor)
{
//Fileに対してXML Documentトークンを一つ作成する
DocumentToken token = new DocumentToken(filePath, str, startLine, startCursor, endLine, endCursor);
return token;
}
}
コメント
コメントを投稿する
SpecialPR