―CAP定理のジレンマをOracle RACで理解する―(2/2)
3. Oracle RACアーキテクチャ
Oracle RACは、共有ディスク有りのActive-Active型クラスタリング構成となります。共有ディスク有りとは、複数のサーバで1つのディスクを共有しデータベースファイルを配置する構成です。Active-Activeは、Webサーバを複数台並べて、ロードバランサで負荷分散を行うのと同じ構成です。複数サーバを並べることにより「パフォーマンス」と「障害復旧性」の向上を図ります。
Webサーバは基本的にステートレスで、状態(データ)を保持しないので、複数台並べやすいのですが、データベースの場合はそう簡単にはいきません。データを管理しますので、「データの同期化」を行う必要があります。
この「データの同期化」が重要なポイントとなります。複雑なアーキテクチャとなりますが、データベース3大原則「パフォーマンス」「データの一貫性」「障害復旧性」を考えれば、理解の助けになるかと思います。
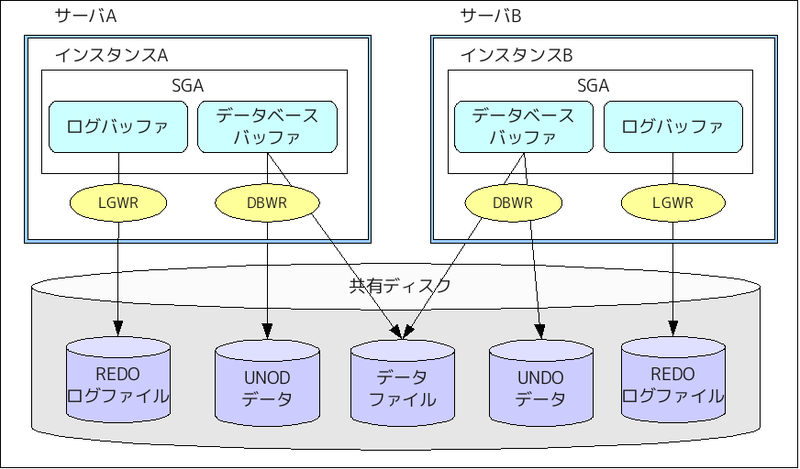
まず、Oracle RACのアーキテクチャを図示します。

AとBの2台のサーバに共有ディスクがつながる構成です。各サーバにインスタンスが存在し、メモリにデータバッファとログバッファが保持されます。共有ディスク上にデータファイルが配置され、REDOログファイルとUNDOデータは、サーバごとに別々のファイルとして配置されます。
なぜ、REDOログファイルとUNDOデータは、サーバ毎に配置されるのでしょうか? データの検索と更新時の動作について、解説しながら説明したいと思います。
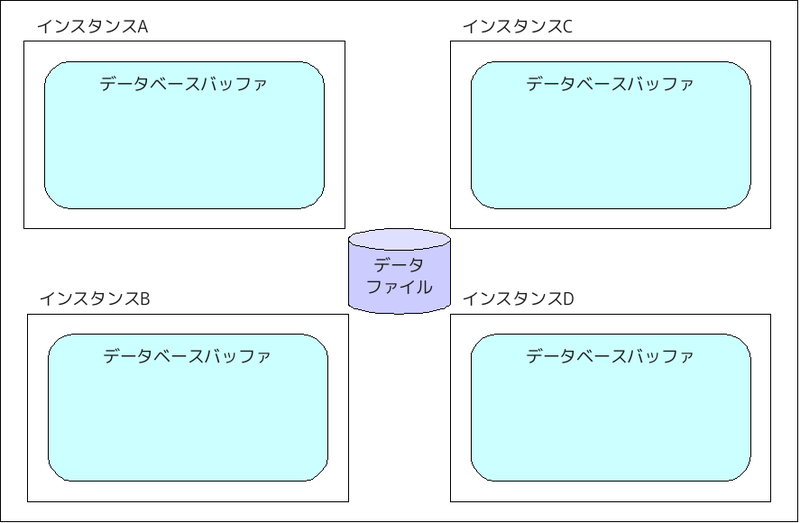
以下のように4サーバでRACを構成した場合を例にとります。

まず、実際の動作の説明の前に、RACを構成するための3大原則を説明します。
3-1. パフォーマンス
パフォーマンスのために、「データ分散」と「インスタンス間のデータ転送」を行います。
- データ分散
効率良く負荷分散を行うために、各サーバにデータを分散して割り当てます。インスタンス起動時にハッシュアルゴリズム(※1)により、該当データを管理するサーバを決定します。実際には、管理されるデータは、レコード単位ではなく、データブロック(※2)と呼ばれる固まりで管理されます。このデータを管理するサーバのことをリソースマスタと呼びます。
(※リソースマスタといいますが、実際にやっていることはリソースの管理「データを保持するのではなく、データがどこにあるかを管理する。」ですので、リソースマネージャという方が適切かと思います……。)
※1:分散処理にかかせないのが、ハッシュアルゴリズムです。クラウドのアーキテクチャを説明する際に必ず出てくるキーワードです。データを分散させ、かつ分散させた場所が後で同じロジックを通せば、特定できるアルゴリズムです。
※2:データを管理するための物理的な最小単位です。 - インスタンス間のデータ転送(キャッシュフュージョン)
4台のサーバは、負荷分散されそれぞれがクライアントから要求を受け付けます。要求を受け付けたサーバが、必要とするデータをデータバッファに確保して、クライアントに返します。その際にデータのありかをリソースマスタに問い合わせます。クラスタ内のどのサーバのインスタンスにも存在しない(まだディスクから読み取られていない)場合、共有ディスクから取得します。あるサーバのインスタンスに存在する場合、データを転送します。
このデータ転送のことをキャッシュフュージョンといいます。 - 要求受付サーバへの キャッシュフュージョン
要求を受け付けたサーバが大量のデータを必要とする場合、データの管理単位であるデータブロックで考えても大量のブロックが必要となります。ブロック毎にリソースマスタが決まりますので、大量のブロックを取得する場合、複数のサーバからキャッシュフュージョンでデータを集めます。
3-2. データの一貫性
クラスタ構成で、データの一貫性を保証するため、「ロックと同期」「障害サーバの切り離し」「サーバをまたぐトランザクション管理」を行います。
- ロックと同期
データバッファは、遅延書き込みにより、データファイルに書き込まれますので、複数インスタンスが存在する場合、データの整合性が崩れてしまいます。これを回避するために、リソースマスタを使用して、データブロック単位でロックを行います。
最新の更新データブロックは、1サーバのみに存在するようにします。但し、「読み取り一貫性」も保証する必要がありますので、トランザクションがCOMMITされる前のデータをUNDOとして保持する必要があります。このUNDOデータは、各サーバで保持されますが、キャッシュフュージョンのタイミングでディスクに書き出されます。サーバ障害によりサーバが切り離される可能性があるためです。
※リソースマスタ管理:「ロックモード(共有モード(参照)・排他モード(更新))」「ロック範囲(ローカル、グローバル)」「UNDOのありなし」で管理します。 - サーバをまたぐトランザクション管理
RACでは負荷分散が行われるため、クライアントの要求が、必ず同じサーバに行くとは限りません。サーバをまたいだトランザクション管理が必要となります。
また、障害により、サーバが切り離された場合であっても、クライアントのトランザクションが継続できないと可用性が良いとはいえません。この仕組みについても、実際の動作にて説明します。
3-3. 障害復旧性
- 障害サーバの切り離し
各サーバと共有ディスクは、SAN(※ 1)等で接続され、各サーバ間はネットワークで接続されます。もし仮にあるサーバのネットワークアダプタのみに障害が発生した場合、データの同期がされていないデータベースバッファがデータファイルに書き込まれる可能性があります。これを回避するために、サーバ間で死活監視を行い、障害が発生したサーバを切り離します。
サーバが切り離された場合でもデータの不整合が起きないようにするための仕組みが必要になります。これについては、実際の動作にて説明します。
※1: Storage Area Network:ストレージ専用の高速ネットワーク。SCSIの後継機的位置づけ。 - リカバリ
もし、RACを構成する全サーバに障害が発生した場合、Oracleはサーバ毎のUNDOデータとREDOログファイルを使用してリカバリを行います。
3-4. データ検索時の動作
それでは、データ検索時にどういった動作になるか説明します。

クライアントからサーバCが、SELECT要求を受け取り、該当データはサーバDが管理するデータブロックであったとします。
- データ要求
クライアントからSELECT要求を受け取ったサーバCは、ハッシュアルゴリズムにより該当データのリソースマスタであるサーバDを割り出し、サーバDにデータ参照要求を送ります。 - ディスク読み取り通知
サーバDのデータバッファに該当データが存在する場合は、サーバCに参照権限でキャッシュフュージョンします。データバッファに存在しない場合、サーバCに共有ディスクから読み取るよう通知します。 - ディスク読み込み
サーバDからディスク読取通知を受け取ったサーバCが共有ディスクからデータを読み込みます。 - バッファ確保
読み込んだデータをサーバCのデータベースバッファに保持します。
※この場合、リソースマスタのサーバDのデータベースバッファにはデータは保持されません。
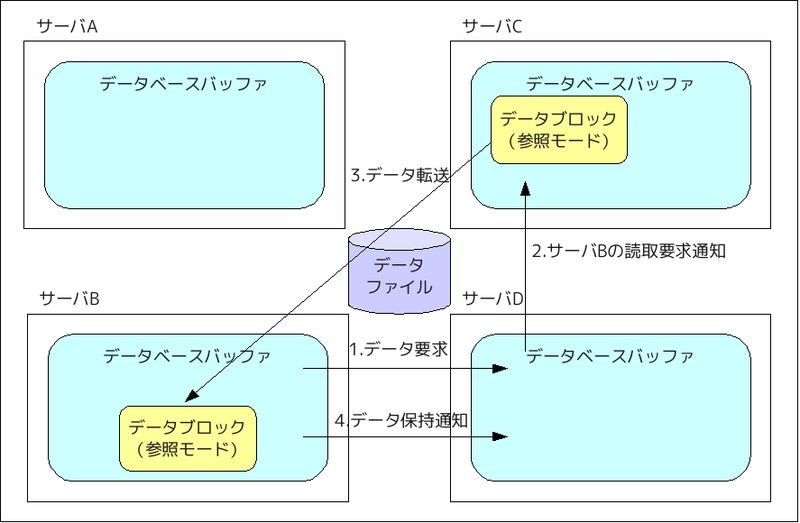
該当データがサーバCのデータベースバッファに保持されている状態で、次にサーバBに同じデータのSELECT要求があった場合は以下のようになります。

{kind=link}
{kind=link}
{kind=link}
- データ要求
クライアントからSELECT要求を受け取ったサーバBは、リソースマスタであるサーバDにデータ参照要求を送ります。 - サーバBの読取要求通知
サーバDは、サーバCにサーバBからの参照要求を通知します。 - データ転送
サーバBからの要求を受け取ったサーバCは、サーバBに参照権限でキャッシュフュージョンを行います。 - データ保持通知
参照モードでデータを保持していることをリソースマスタに通知します。
※今後、同じデータブロックの参照要求が来た場合に備えるためです。
3-5. データ更新時の動作
該当データがサーバCのデータベースバッファに保持されている状態で、サーバBが同じデータブロックの更新要求があった場合の動作は、以下のようになります。

- データ要求
クライアントから更新要求を受け取ったサーバAは、リソースマスタであるサーバDにデータ更新要求を送ります。 - サーバAの読取要求通知
サーバDは、サーバBにサーバAからの更新要求を通知します。 - データ転送
サーバAからの要求を受け取ったサーバBは、サーバAに更新権限でキャッシュフュージョンを行います。サーバBが保持していたデータブロックは、UNDO情報として保持します。
※サーバAで更新されるデータが最新版となるためです。
また、キャッシュフュージョンのタイミングで、UNDO情報とREDOログバッファを共有ディスクに書き出します。
※障害発生時のサーバ切り離しに備えるためです。 - データ保持通知
更新モードでデータを保持していることをリソースマスタに通知します。
3-6. Oracle RACのボトルネックとCAP定理について
Oracle RACの検索、更新時の動作を説明しましたが、いかがだったでしょうか?
検索に比べて、更新時の動作が複雑であったかと思います。幾分か説明を端折っている個所もありますので、実際にはより複雑な同期処理を行っています。ここで、CAP定理の話に戻りますと、Oracle RACは、CAPを満たしているといえるでしょうか?
まず、P(サーバの台数)を増やした場合を考えてみます。RACを構成するサーバを1000台に増やすことは可能でしょうか? 残念ながら、現実的ではありませんし、わたしの知る限りでは事例は存在しません。せいぜい数十台レベルです。サーバの台数を増やした場合、それに比例してデータの分散率が増えます。その結果、データの同期処理が多くなりパフォーマンスが劣化します。
Oracle RACでよく発生するボトルネックは、データ同期処理であるキャッシュフュージョンです。
Pを満たし、C(データの一貫性)を確保しようとすると、同期処理やロック処理に時間がかかり、ユーザの要求に対して待ちが発生します。つまり、A(システムの可用性)を満たすことができなくなります。
現実的には、CAPそれぞれのバランスを取りながら設計することになります。
クラウドの場合も同じようにAとPを保証し、Cに関しては「Eventually Consistency」という考え方で対応する形となります。
4. 参考資料
- 2009年4月号 総合特集「クラウドをつかむ」
- DB Magazine 2004年9月号 特集「徹底解剖Oracle 10g」
- 「Oracle 10g 真剣勝負」翔泳社刊
- 「絵で見てわかるOracleの仕組み」翔泳社刊
- WikiPedia 「ACID」