第036回_XMLParserクラスの実装他
»
今回は、
各パーツを呼び出すXMLParserクラスと(無条件)字句解析器を表すLexerクラスの作成、
以前紹介したDocumentTokenizerクラスの修正、
TestXMLParserクラスからXMLParserを呼び出すサンプルの紹介
をします。
各パーツを呼び出すXMLParserクラスと(無条件)字句解析器を表すLexerクラスの作成、
以前紹介したDocumentTokenizerクラスの修正、
TestXMLParserクラスからXMLParserを呼び出すサンプルの紹介
をします。
XMLParserの実装
XMLParserは、字句解析器、構文解析器、意味解析器(未実装)の粒度のモジュールを呼び出し、制御するクラスとします。
色々な処理モードを分ける場合はこのクラスを修正または拡張するものとします。
尚、エラー処理に例外を使っていないのは例外処理の検討をしていないためであり、本来は例外で処理すべき部分もありますのでご注意ください。
色々な処理モードを分ける場合はこのクラスを修正または拡張するものとします。
尚、エラー処理に例外を使っていないのは例外処理の検討をしていないためであり、本来は例外で処理すべき部分もありますのでご注意ください。
public class XmlParser
{
private static XmlParser m_instance = new XmlParser();
private static ElementTable m_elementTable = ElementTable.getInstance();
private Lexer m_lex;
private boolean m_hasError;
//シングルトンパターン
private XmlParser()
{
m_lex = Lexer.getInstance();
m_hasError = false;
}
public static XmlParser getInstance()
{
return m_instance;
}
//xmlファイルを解析する
public void parse(String filePath)
{
//無条件字句解析を実施する
m_lex.analyze(filePath);
//無条件字句解析の結果にエラーがあるか判定する
m_hasError = m_lex.hasError();
//構文解析する
this.analyzeSyntax();
}
private void analyzeSyntax()
{
//既にエラーがある場合
if (m_hasError)
{
//何もしない
}
//まだエラーがない場合
else
{
//抽象構文木作成visitorを作成する
SyntaxParserVisitor v = new SyntaxParserVisitor();
//EBNFツリーのルートノードを取得する
EbnfNodeAcceptor node = SyntaxTree.getInstance().getRoot();
//EBNFデータツリーを巡回して、構文解析する
node.accept(v);
m_hasError &= v.getResult();
}
}
}
Lexerの検討と実装
XMLParserの内部で呼び出すLexerについて説明します。
Lexerは、Lexer内でDocumentTokenizerを使ってDocumentTokenを生成し、TokenManagerにDocumentTokenを登録する役割を担います。
以前に説明したように条件付字句解析器は構文解析器の中にありますから、XMLパーサから見た字句解析器は無条件字句解析だけを実行します。
これによって、全体のソフトウェア構成を次のように修正します。
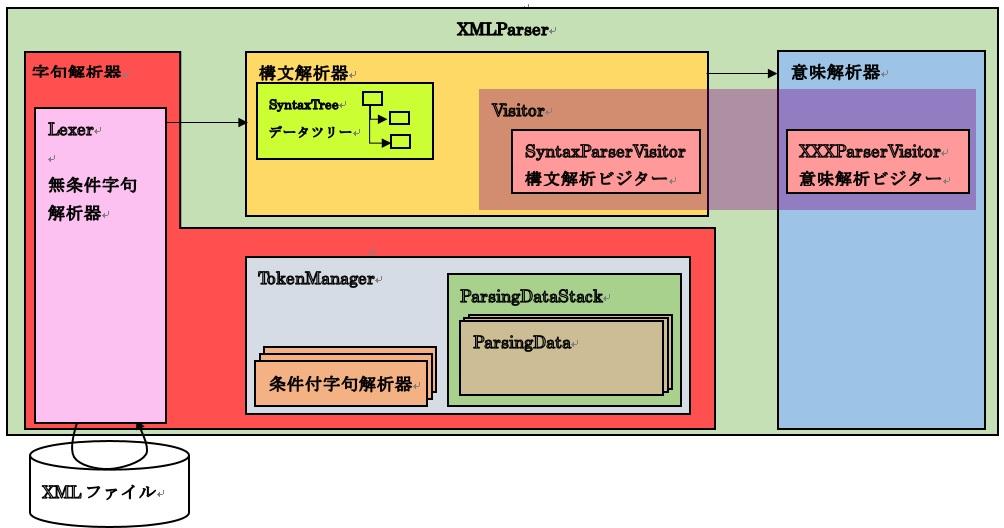
036-1.ソフトウェア構成図
Lexerは、Lexer内でDocumentTokenizerを使ってDocumentTokenを生成し、TokenManagerにDocumentTokenを登録する役割を担います。
以前に説明したように条件付字句解析器は構文解析器の中にありますから、XMLパーサから見た字句解析器は無条件字句解析だけを実行します。
これによって、全体のソフトウェア構成を次のように修正します。

public class Lexer
{
private static Lexer m_instance = new Lexer();
private static TokenManager m_tokenManager = TokenManager.getInstance();
private boolean m_hasError;
private Lexer()
{
m_hasError = false;
}
public static Lexer getInstance()
{
return m_instance;
}
public void analyze(String path)
{
//Documentトークナイザを作成する
DocumentTokenizer dt = new DocumentTokenizer(path);
//ファイルの内容をトークン化する
dt.tokenize();
m_hasError = dt.hasError();
//作成したトーク列を取り出す
DocumentToken token = dt.getToken();
//トークン管理に設定する
m_tokenManager.setDocumentToken(token);
}
public boolean hasError()
{
return m_hasError;
}
}
DocumentTokenizerの修正
以前に説明したDocumentTokenizerからExtSubsetやExtParsedEntと共通する処理を抜き出して、親クラスBaseFileTokenizerを作成します。
■BaseFileTokenizer
■BaseFileTokenizer
public abstract class BaseFileTokenizer
{
static private final String ms_errorMessage
= "cause:can't contain RestrictedChar [%c]";
private RestrictedCharMap m_map;
private BufferedReader m_br;
private DocumentToken m_token;
private int m_lineNum;
private boolean m_hasRestrictedChar;
private String m_errorMessage;
private String m_filePath;
//コンストラクタ
public BaseFileTokenizer(String path)
{
m_map = new RestrictedCharMap();
m_br = getBR(path);
m_token = null;
m_lineNum = 0;
m_hasRestrictedChar = false;
m_errorMessage = "";
m_filePath = path;
}
//トークン化する
public void tokenize()
{
String buffer="";
int lastCursor=-1;
//無限ループ
while(true)
{
try
{
//1行読み込む
String str = m_br.readLine();
//EOFに到達している場合
if (str == null)
{
break;
}
//EOFに到達していない場合
else
{
//読み込み行数を加算する
//(初期値0なので1行目から加算してOK)
m_lineNum++;
//文字列を追加する
buffer+=str;
//行文字列にRestrictedCharが入っていないかチェックする
m_hasRestrictedChar |= containsRestrictChar(str);
//改行文字が抜けてしまうので追加する
buffer+="\n";
lastCursor = str.length();
}
}
catch (IOException e)
{
e.printStackTrace();
}
}
//Fileに対してXML Documentトークンを一つ作成する
m_token = makeToken(m_filePath, buffer, 0,0,m_lineNum,lastCursor);
}
protected abstract BufferedReader getBR(String path);
protected abstract DocumentToken makeToken(String filePath,String str,
int startLine, int startCursor,
int endLine, int endCursor);
private boolean containsRestrictChar(String str)
{
//戻り値
boolean retval = false;
//カーソル
int cursor = 0;
boolean containsRestrictChar = m_map.containsRestrictChar(str);
//RestrictedCharの場合
if (containsRestrictChar)
{
String message = String.format(ms_errorMessage, str);
//errorメッセージに追加する
m_errorMessage = m_lineNum+":"+cursor+"|"+message;
//戻り値をtrueにする
retval = true;
}
//RestrictedCharでない場合
else
{
//何もしない
}
return retval;
}
public void putMessageIfError()
{
//RestrictedCharを持っている場合
if (m_hasRestrictedChar)
{
System.out.println(m_errorMessage);
}
//RestrictedCharを持っていない場合
else
{
//何もしない
}
}
public DocumentToken getToken()
{
return m_token;
}
public boolean hasError()
{
return m_hasRestrictedChar;
}
}
■DocumentTokenizer
public class DocumentTokenizer extends BaseFileTokenizer
{
//コンストラクタ
public DocumentTokenizer(String path)
{
super(path);
}
@Override
protected BufferedReader getBR(String path)
{
BufferedReader br = null;
//FileReaderを作成し、1行トークナイザに設定する
try
{
File file = new File(path);
FileReader filereader;
filereader = new FileReader(file);
br = new BufferedReader(filereader);
}
catch (FileNotFoundException e)
{
// TODO 自動生成された catch ブロック
e.printStackTrace();
}
return br;
}
@Override
protected DocumentToken makeToken(String filePath,
String str, int startLine, int startCursor,
int endLine, int endCursor)
{
//Fileに対してXML Documentトークンを一つ作成する
DocumentToken token
= new DocumentToken(filePath, str, startLine, startCursor,
endLine, endCursor);
return token;
}
}
サンプル:TestXMLParser
自作のXMLパーサを実際に実行するテストクラスは次のようにしておきます。
public class TestXmlParser
{
public static void main(String args[])
{
try
{
//XMLParserを作る
XmlParser xmlParser = XmlParser.getInstance();
//対象ファイルを指定し、そのファイルを解析する
xmlParser.parse(args[0]);
}
catch (Exception e)
{
System.out.println("XmlParser not Start\n");
System.out.println(e.getMessage());
e.printStackTrace();
}
}
}
コメント
コメントを投稿する
SpecialPR