第024回_字句解析の共通クラス3_MapSwitchLexer他
»
今回も共通クラスについて検討します。
# 次回から字句解析器を作りますからご容赦ください。
m_eofFunctorのフィールド
を持ちます。それ以外はIntegerRangeKeyMapのラッパーメソッドを実装します。
■LexicalMapの実装
実装は次のようになります。
■Functorの実装
LexicalMapに出てきたFunctorの実装は次のようになります。
■立ち位置
実装は次のようになります。
「初期化せず、次の文字へ移動する処理」
「初期化して、今の文字を確定する処理」
が繰り返し出てきます。
そこで、
「初期化せず、次の文字へ移動する処理」
pos++を実行する
「初期化して、今の文字を確定する処理」
m_tokenBuilder.initStart(m_char); と、pos++を実行する
となるファンクタMovePosとInit_MovePosを用意します。
■追加機能
また複数の表を管理するクラスとしてMultipleMapsSwitchTokenizerを用意します。
■立ち位置
# 次回から字句解析器を作りますからご容赦ください。
条件付字句解析器の実装パターン
前にも述べましたが、この自作XMLパーサの役割分担は
1文字目による分岐を条件付字句解析器
2文字目以降の処理をトークナイザ
が担当します。
■なぜそのような構造にするか(設計理由)
if-else文を減らすためにパターンマッチングがやっぱり良いのではと思われるかもしれませんが、上記のまとめた表は正規表現にしているわけではありません。ここで行うべきは表をあらわす基礎クラスを作ることです。その基礎クラスを使えばif-else文を減らすことができるでしょう。
1文字目による分岐を条件付字句解析器
2文字目以降の処理をトークナイザ
が担当します。
■なぜそのような構造にするか(設計理由)
トークンを切り出す方法として簡単なのはパターンマッチングです。パターンマッチングの実施の仕方にもよりますが、おおよそ先頭からの文字列に対して文字列パターンの評価を行います。何の条件もない文字列の場合はパターンマッチングの処理が最善です。しかし、形式言語の対象文字列の場合はトークンの切り出し始め(1文字目)の意味が大きい、つまり条件付の文字列であるので、その処理の実装としてパターンマッチングは最善ではありません。
では、ある条件付字句解析器Xの処理について考えてみましょう。
ある条件付字句解析器Xはトークンバッファの先頭文字を取得して
という機能を持つように整理できます。これらを生真面目に作っていくとif-else文が多くなってメンテナンス性が低下します。| 次の文字 | 処理 |
| ------------------ | |
| α | トークナイザAを呼び出す |
| β | トークナイザBを呼び出す |
| γ | トークナイザCを呼び出す |
| ・・・・・・ | |
| その他 | トークナイザZを呼び出す |
| EOF | トークンXXを作成する |
if-else文を減らすためにパターンマッチングがやっぱり良いのではと思われるかもしれませんが、上記のまとめた表は正規表現にしているわけではありません。ここで行うべきは表をあらわす基礎クラスを作ることです。その基礎クラスを使えばif-else文を減らすことができるでしょう。
LexicalMapとFunctor
表を扱うことから無条件字句解析器で説明したIntegerRangeKeyMapをcompositeしたLexicalMapを作成します。先の表の内容からLexicalMapは、EOFの場合の処理を設定できる必要があるため、m_eofFunctorのフィールド
を持ちます。それ以外はIntegerRangeKeyMapのラッパーメソッドを実装します。
■LexicalMapの実装
実装は次のようになります。
public class LexicalMap
{
private final IntegerRangeKeyMap<Functor> m_map;
private Functor m_eofFunctor;
public LexicalMap()
{
m_map = new IntegerRangeKeyMap<Functor>();
}
public void setEofFunctor(Functor f)
{
m_eofFunctor = f;
}
public void put(int key, Functor f)
{
m_map.put(key, f);
}
public void put(int lower, int upper, Functor f)
{
m_map.put(lower, upper , f);
}
public void setOutOfRange(Functor f)
{
m_map.setOutOfRange(f);
}
public Functor get(int key)
{
return m_map.get(key);
}
public Functor getEofFunctor()
{
return m_eofFunctor;
}
}
LexicalMapに出てきたFunctorの実装は次のようになります。
public interface Functor
{
public Token tokenize(StringBuilder str, int pos);
}
MapSwitchLexer
LexicalMapを持ち、ConditionLexerを継承したMapSwitchLexerクラスを用意します。■立ち位置
立ち位置は次のようになります。
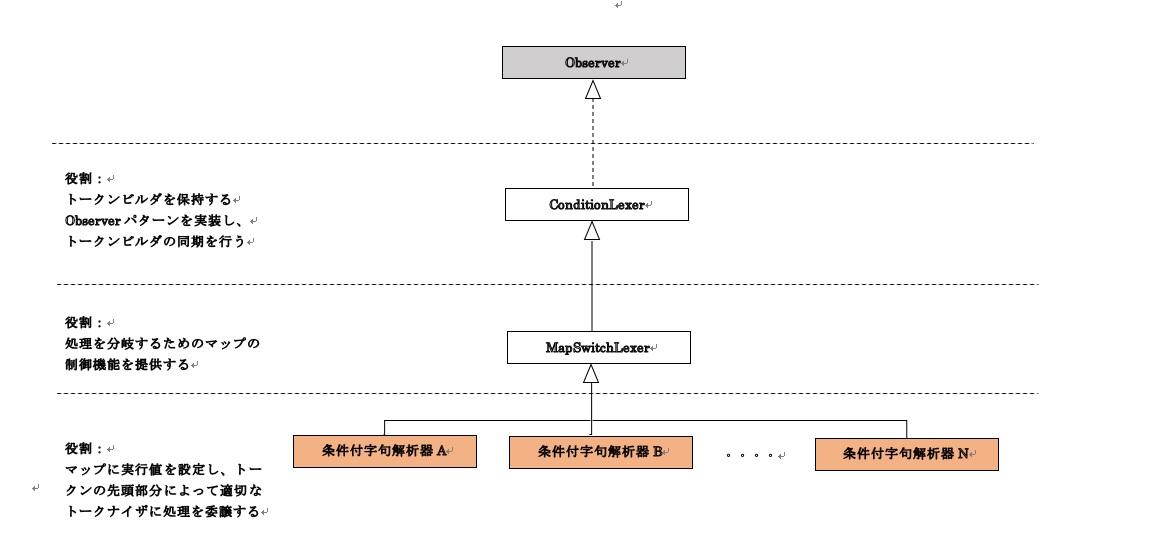
24-1.クラス設計
■実装
実装は次のようになります。
public abstract class MapSwitchLexer extends ConditionLexer
{
protected final LexicalMap m_map;
protected char m_char;
protected MapSwitchLexer()
{
m_map = new LexicalMap();
m_char = '0';
}
@Override
public Token nextToken(StringBuilder str)
{
Token retval = null;
//文字列長を数える
int len = str.length();
//文字列長が0より大きい場合
if (len > 0)
{
//先頭文字を取り出す
m_char = str.charAt(0);
Functor f = m_map.get(m_char);
retval = f.tokenize(str, 0);
}
//文字列長が0の場合
else
{
//EOF時の対応ファンクタを実行する
retval = m_map.getEofFunctor().tokenize(str, 0);
}
return retval;
}
}
MapSwitchLexerの追加機能
いくつかの条件付字句解析器が持つ表の中で、「初期化せず、次の文字へ移動する処理」
「初期化して、今の文字を確定する処理」
が繰り返し出てきます。
そこで、
「初期化せず、次の文字へ移動する処理」
pos++を実行する
「初期化して、今の文字を確定する処理」
m_tokenBuilder.initStart(m_char); と、pos++を実行する
となるファンクタMovePosとInit_MovePosを用意します。
■追加機能
public abstract class MapSwitchLexer extends ConditionLexer
{
protected class MovePos implements Functor
{
private final Functor m_f;
public MovePos(Functor f)
{
m_f = f;
}
@Override
public Token tokenize(StringBuilder str, int pos)
{
Token retval = null;
pos++;
retval = m_f.tokenize(str, pos);
return retval;
}
}
protected class Init_MovePos extends MovePos
{
public Init_MovePos(Functor f)
{
super(f);
}
@Override
public Token tokenize(StringBuilder str, int pos)
{
Token retval = null;
m_tokenBuilder.initStart(m_char);
retval = super.tokenize(str, pos);
return retval;
}
}
・・・・
}
TermTokenizerの修正
LexicalMapの処理部分からトークナイザを呼び出すためにTermTokenizerにFunctorインタフェースをimplementsします。
public abstract class TermTokenizer
implements Observer , Functor //追加
{
・・・・
}
MapSwitchTokenizerとMultipleMapsSwitchTokenizer
MapSwitchLexerと同じような立ち位置で表を管理するトークナイザの基底クラスとしてMapSwitchTokenizerを用意します。また複数の表を管理するクラスとしてMultipleMapsSwitchTokenizerを用意します。
■立ち位置
立ち位置は次のようになります。
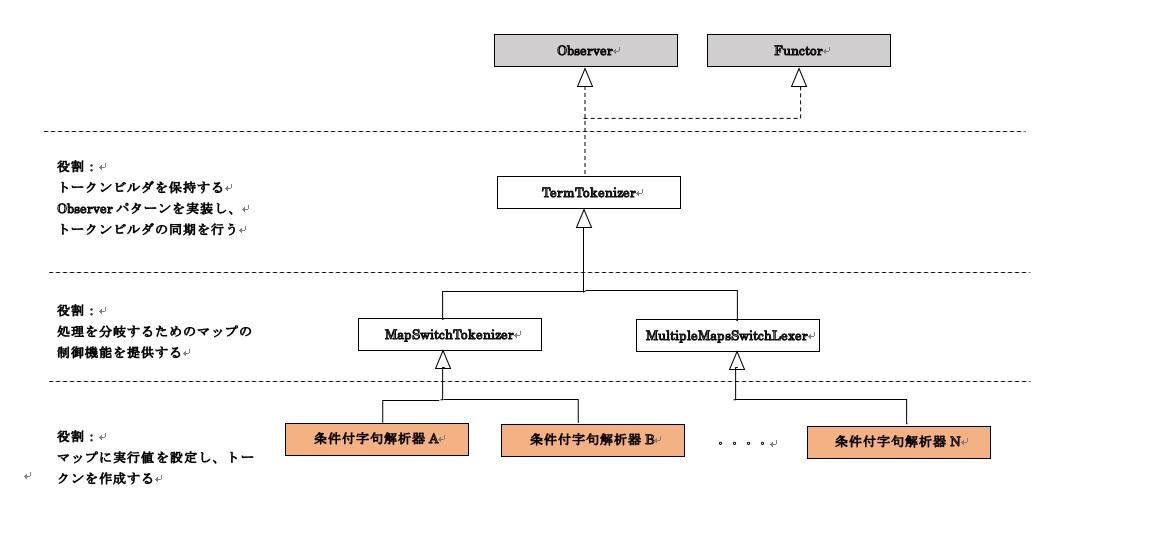
24-2.クラス設計
■MapSwitchTokenizerの機能と実装
MapSwitchLexerと処理はほぼ同じですが、ファンクタとして「updateして、posを移動する」の機能のUpdate_MovePosを用意します。
実装は次のようになります。
■MultipleMapsSwitchTokenizerの機能と実装実装は次のようになります。
public abstract class MapSwitchTokenizer extends TermTokenizer
{
protected class Update_MovePos implements Functor
{
public Update_MovePos(){}
@Override
public Token tokenize(StringBuilder str, int pos)
{
m_tokenBuilder.update(m_char);
pos++;
return MapSwitchTokenizer.this.tokenize(str, pos);
}
}
protected final LexicalMap m_map;
protected char m_char;
public MapSwitchTokenizer()
{
m_map = new LexicalMap();
m_char = '0';
}
public Token tokenize(StringBuilder str, int pos)
{
Token retval = null;
//文字列長を数える
int len = str.length();
//文字列長がposより大きい場合
if (len > pos)
{
//先頭文字を取り出す
m_char = str.charAt(pos);
Functor f = m_map.get(m_char);
retval = f.tokenize(str, pos);
}
//文字列長がposより小さい場合
else
{
//EOFに到達したのでそれまでのトークンを返す
retval = m_map.getEofFunctor().tokenize(str, pos);
}
return retval;
}
}
MultipleMapsSwitchTokenizerの動作はMapSwitchTokenizerとほぼ同じでマップをArrayListで管理するところが異なります。
また、いくつかの条件付字句解析器が持つ表は、
「posを移動する」
「updateして、posを移動する」
「マップを移動する」
「posを移動して、マップを移動する」
「update、posを移動、マップを移動する」
「指定範囲をupdate、posを移動、マップを移動する」
「初期化、指定範囲をupdate、posを移動、マップを移動する」
が繰り返し出てくるので、内部クラスを定義します。
実装は次のようになります。
これで共通クラスの説明は終わりになります。次回からは実際に条件付字句解析器を作成していきます。
また、いくつかの条件付字句解析器が持つ表は、
「posを移動する」
「updateして、posを移動する」
「マップを移動する」
「posを移動して、マップを移動する」
「update、posを移動、マップを移動する」
「指定範囲をupdate、posを移動、マップを移動する」
「初期化、指定範囲をupdate、posを移動、マップを移動する」
が繰り返し出てくるので、内部クラスを定義します。
実装は次のようになります。
public abstract class MultipleMapsSwitchTokenizer extends TermTokenizer
{
protected class MovePos implements Functor
{
private final Functor m_f;
public MovePos(Functor f)
{
m_f = f;
}
@Override
public Token tokenize(StringBuilder str, int pos)
{
Token retval = null;
pos++;
retval = m_f.tokenize(str, pos);
return retval;
}
}
//今の文字を決定したトークンとしてFunctor f を実行する
protected class Update_MovePos extends MovePos
{
public Update_MovePos(Functor f)
{
super(f);
}
@Override
public Token tokenize(StringBuilder str, int pos)
{
m_tokenBuilder.update(m_char);
return super.tokenize(str, pos);
}
}
//pos-startからpos-endまでの文字を決定したトークンとしてFunctor f を実行する
protected class UpdateRange_MovePos extends MovePos
{
private final int m_start;
private final int m_end;
public UpdateRange_MovePos(Functor f, int start, int end)
{
super(f);
m_start = start;
m_end = end;
}
@Override
public Token tokenize(StringBuilder str, int pos)
{
for(int i=pos-m_start; i <= pos-m_end; i++)
{
char current = str.charAt(i);
m_tokenBuilder.update(current);
}
return super.tokenize(str, pos);
}
}
//initもするpos-startからpos-endまでの文字を決定したトークンとしてFunctor f を実行する
protected class InitUpdateRange_MovePos extends MovePos
{
private final int m_start;
private final int m_end;
public InitUpdateRange_MovePos(Functor f, int start, int end)
{
super(f);
m_start = start;
m_end = end;
}
@Override
public Token tokenize(StringBuilder str, int pos)
{
char first = str.charAt(pos-m_start);
m_tokenBuilder.initStart(first);
for(int i=pos-m_start+1; i <= pos-m_end; i++)
{
char current = str.charAt(i);
m_tokenBuilder.update(current);
}
return super.tokenize(str, pos);
}
}
protected class MoveMap implements Functor
{
//移動先のマップのindex
private int m_index;
public MoveMap(int index)
{
m_index = index;
}
@Override
public Token tokenize(StringBuilder str, int pos)
{
MultipleMapsSwitchTokenizer.this.m_currentIndex = m_index;
return MultipleMapsSwitchTokenizer.this.tokenize(str, pos);
}
}
protected class MovePos_MoveMap extends MoveMap
{
public MovePos_MoveMap(int index)
{
super(index);
}
@Override
public Token tokenize(StringBuilder str, int pos)
{
pos++;
return super.tokenize(str, pos);
}
}
protected class Update_MovePos_MoveMap extends MovePos_MoveMap
{
public Update_MovePos_MoveMap(int index)
{
super(index);
}
@Override
public Token tokenize(StringBuilder str, int pos)
{
m_tokenBuilder.update(m_char);
return super.tokenize(str, pos);
}
}
protected class UpdateRange_MovePos_MoveMap extends MovePos_MoveMap
{
private final int m_start;
private final int m_end;
public UpdateRange_MovePos_MoveMap(int index, int start, int end)
{
super(index);
m_start = start;
m_end = end;
}
@Override
public Token tokenize(StringBuilder str, int pos)
{
for(int i=pos-m_start; i <= pos-m_end; i++)
{
char current = str.charAt(i);
m_tokenBuilder.update(current);
}
return super.tokenize(str, pos);
}
}
protected class InitUpdateRange_MovePos_MoveMap extends MovePos_MoveMap
{
private final int m_start;
private final int m_end;
public InitUpdateRange_MovePos_MoveMap(int index, int start, int end)
{
super(index);
m_start = start;
m_end = end;
}
@Override
public Token tokenize(StringBuilder str, int pos)
{
char first = str.charAt(pos-m_start);
m_tokenBuilder.initStart(first);
for(int i=pos-m_start+1; i <= pos-m_end; i++)
{
char current = str.charAt(i);
m_tokenBuilder.update(current);
}
return super.tokenize(str, pos);
}
}
protected final ArrayList<LexicalMap> m_mapList;
protected int m_startIndex;
protected int m_currentIndex;
protected char m_char;
public MultipleMapsSwitchTokenizer()
{
m_mapList = new ArrayList<LexicalMap>();
m_startIndex = 0;
m_currentIndex = 0;
m_char = '0';
}
public Token tokenize(StringBuilder str, int pos)
{
Token retval = null;
//文字列長を数える
int len = str.length();
//文字列長がposより大きい場合
if (len > pos)
{
//先頭文字を取り出す
m_char = str.charAt(pos);
Functor f = m_mapList.get(m_currentIndex).get(m_char);
retval = f.tokenize(str, pos);
}
//文字列長がposより小さい場合
else
{
Functor f = m_mapList.get(m_currentIndex).getEofFunctor();
//EOFに到達したのでそれまでのトークンを返す
retval = f.tokenize(str, pos);
}
//次のためにindexを初期化する
m_currentIndex = m_startIndex;
return retval;
}
}
コメント
コメントを投稿する
SpecialPR