第023回_字句解析の共通クラス2_TermTokenizer_TokenBuilder
»
前回の続きでTermTokenizerの実装をした後、TokenBuilderクラスの解説・実装をします。
■立ち位置
立ち位置は次のようになります。
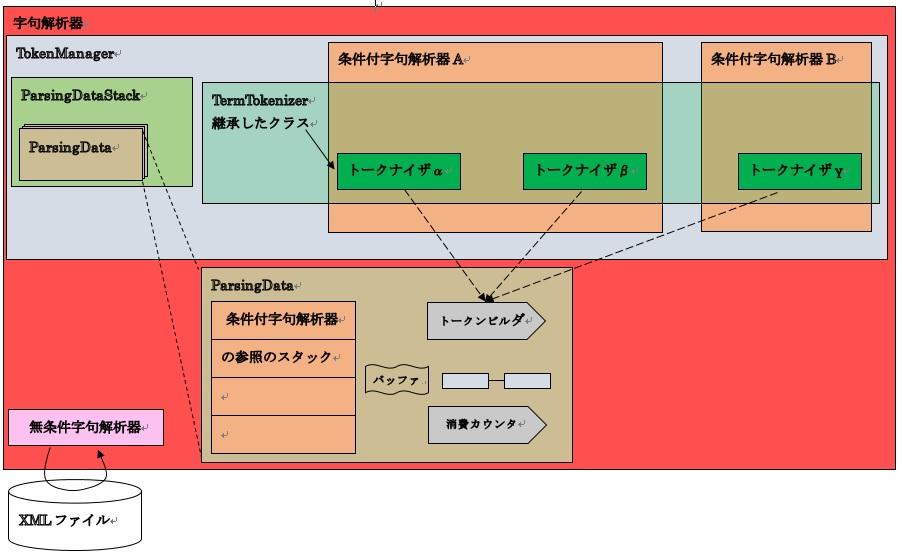
23-1.ソフトウェア構成図
トークナイザがトークンを生成し、トークンリストに登録する流れは次のようになります。
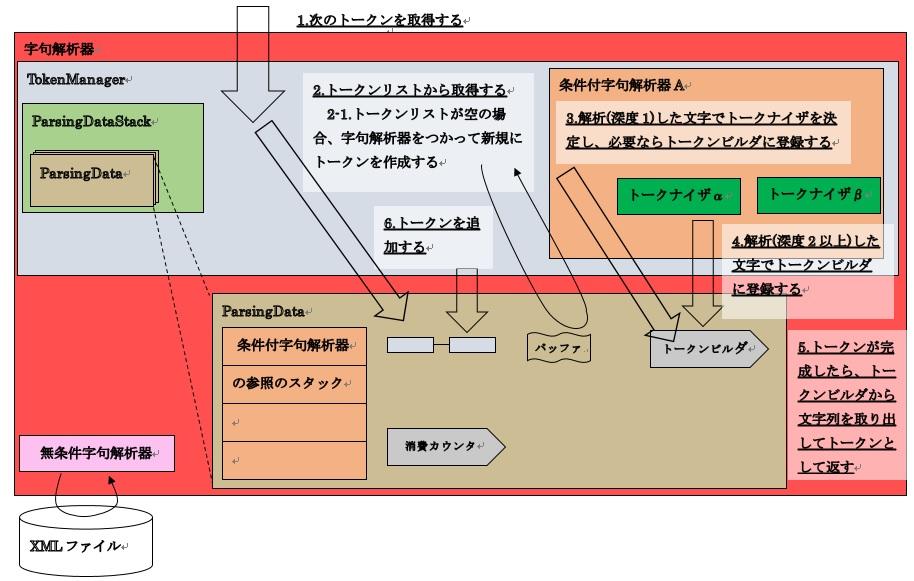
23-2.トークナイザを使ったトークンの生成・トークンリスト登録の流れ
■実装
実装は次のようにします。
TermTokenizer
TermTokenizerは、字句解析において解析深度2以上を担当するトークナイザの共通の親クラスです。必要な機能はConditionLexerと同じです。ただしクラス単位は異なるので別クラスとして用意します。■立ち位置
立ち位置は次のようになります。

トークナイザがトークンを生成し、トークンリストに登録する流れは次のようになります。

■実装
実装は次のようにします。
public abstract class TermTokenizer
implements Observer
{
protected static ParsingDataStack m_parsingData
= ParsingDataStack.getInstance();
protected TokenBuilder m_tokenBuilder;
public TermTokenizer()
{
m_parsingData.addObserver(this);
m_tokenBuilder = m_parsingData.getTokenBuilder();
}
public abstract Token tokenize(StringBuilder str, int pos);
//オブザーバパターン
public void update()
{
m_tokenBuilder = m_parsingData.getTokenBuilder();
}
}
TokenBuilder
設計した後、実装を行います。
■役割
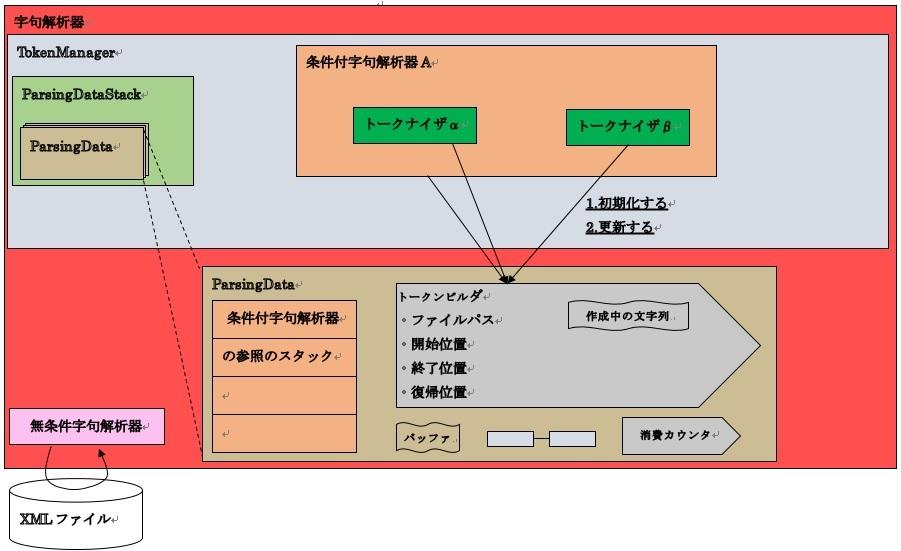
23-3.ソフトウェア構成図
■解析位置を示すAnalyzePositionクラス
■役割
TokenBuilderは未完成のトークンを示します。TokenBuilderに1文字ずつ詰めていき、完成したところでトークナイザの指示でTokenクラスに文字列を渡します。
■機能
TokenBuilderに必要な機能は、
とします。
■準正常系のためのファイル位置情報| 1. | 構成中のトークンを示す文字列を保持する |
| 2. | 準正常系のために、 ファイル名 解析開始地点--ファイル上の開始位置(行数、行頭からのカーソル位置)-- 現在のファイル位置(行数、行頭からのカーソル位置) を保持する |
| 3. | 1つ前の文字を保持する(開始位置の行数を更新するためには1つ前の文字が改行コードか判定する必要があります。) |
| 4. | トークンを消費せずにトークンリストをクリアしたときに現在の解析地点をバックトレースするためのリスタート位置を保持する |
構文解析器がトークンと構文を比較してNGとしたとき、その位置がわからないと修正するのが大変になるのでトークンのファイル内の位置情報を保持することにします。
ファイル名に関しては、TokenBuilderに保持する方法とログファイルにファイル名を出力しておき、処理区間を判別する方法が簡単に実装できると思います。今回はTokenBuilderにファイル名を保持するようにします。理由はログを切り出したり、ローテーションでファイルの内容が分断したりする可能性があると、ログファイルに出力したファイル名から処理区間を判定するのが面倒になるからです。
■立ち位置ファイル名に関しては、TokenBuilderに保持する方法とログファイルにファイル名を出力しておき、処理区間を判別する方法が簡単に実装できると思います。今回はTokenBuilderにファイル名を保持するようにします。理由はログを切り出したり、ローテーションでファイルの内容が分断したりする可能性があると、ログファイルに出力したファイル名から処理区間を判定するのが面倒になるからです。

■解析位置を示すAnalyzePositionクラス
トークンビルダの開始位置、終了位置、復帰位置を示すAnalyzePositionクラスを用意します。
実装は次のようになります。
■TokenBuilderの実装実装は次のようになります。
public class AnalyzePosition
{
//上から何行目か
private int m_line;
//左端から何文字目か
private int m_cursor;
//1つ前の文字
private char m_previous;
public AnalyzePosition(int line, int cursor, char previous)
{
m_line = line;
m_cursor = cursor;
m_previous = previous;
}
public AnalyzePosition(AnalyzePosition from)
{
m_line = from.m_line;
m_cursor = from.m_cursor;
m_previous = from.m_previous;
}
public void update(char c)
{
//一文字前が改行文字の場合
if (
(m_previous == '\n')
|| (m_previous == '\r')
)
{
m_line++;
m_cursor=1;
}
//一文字前が改行文字でない場合
else
{
m_cursor++;
}
m_previous = c;
}
public int getLine()
{
return m_line;
}
public int getCursor()
{
return m_cursor;
}
}
AnalyzePositionクラスと先の検討を踏まえて、実装は次のようになります。
■TokenBuilderにファイルパスを渡すための修正
public class TokenBuilder
{
//ファイルパス,ファイル名
private String m_filePath;
//作成途中のトークンの文字列
private StringBuilder m_tokeningStr;
//字句解析器がリスタートしたときの再開ポイント
private AnalyzePosition m_restart;
//トークンの文字列の1文字目の位置
private AnalyzePosition m_start;
//作成中のトークンの今のところ1番後ろの文字の位置
private AnalyzePosition m_current;
public TokenBuilder(String filePath)
{
m_filePath = filePath;
m_tokeningStr = null;
m_restart = null;
m_start = null;
//最初の処理が上手く行くようにpreviousに改行文字を設定する
m_current = new AnalyzePosition(0,0,'\n');
}
//空でTokenBuilderを使う場合に呼び出す
public void initStart()
{
m_restart = new AnalyzePosition(m_current);
m_start = new AnalyzePosition(m_current);
m_tokeningStr = new StringBuilder();
}
public void initStart(char c)
{
m_restart = new AnalyzePosition(m_current);
m_current.update(c);
m_start = new AnalyzePosition(m_current);
m_tokeningStr = new StringBuilder();
m_tokeningStr.append(c);
}
public void update(char c)
{
m_tokeningStr.append(c);
m_current.update(c);
}
public void update(String str)
{
for(char c : str.toCharArray())
{
this.update(c);
}
}
public String getFilePath()
{
return m_filePath;
}
public String getString()
{
return m_tokeningStr.toString();
}
public int getStartLine()
{
return m_start.getLine();
}
public int getStartCursor()
{
return m_start.getCursor();
}
public int getLine()
{
return m_current.getLine();
}
public int getCursor()
{
return m_current.getCursor();
}
public void clear()
{
//トークンを消費しなかった場合、initStart()の前の位置に戻す
m_current = new AnalyzePosition(m_restart);
}
}
TokenBuilderにファイルパスを渡すために、ParsingDataクラスのインタフェースを修整します。
修正の影響を受けて呼び出し元のParingDataStackも修正します。
さらに、パラメータ実体のためのコンテキストの場合はファイルパスにパラメータ実体名を追加したいのでParsingDataStackのインタフェースを追加し,呼び出し元のTokenManagerも修正します。
ParsingDataの修正
ParsingDataStackの修正
TokenManagerの修正修正の影響を受けて呼び出し元のParingDataStackも修正します。
さらに、パラメータ実体のためのコンテキストの場合はファイルパスにパラメータ実体名を追加したいのでParsingDataStackのインタフェースを追加し,呼び出し元のTokenManagerも修正します。
ParsingDataの修正
public abstract class ParsingData
{
・・・・
//引数にファイルパスを追加
public ParsingData(String filePath, StringBuilder newBuffer)
{
・・・
m_tokenBuilder = new TokenBuilder(filePath);
・・・
}
・・・・
}
public class ParsingDataStack
{
・・・・
//修正
public void newContext(DocumentToken t)
{
StringBuilder str = new StringBuilder();
str.append(t.getStr());
String filePath = t.getFilePath();
m_data.push(new ParsingData(filePath, str));
this.notifyObserver();
}
//追加
public void newContext(String parameterName, StringBuilder newBuffer)
{
BaseParsingData pd = m_data.peek();
TokenBuilder tb = pd.getTokenBuilder();
String path = tb.getFilePath() +"-->"+ parameterName;
m_data.push(new ParsingData(path, newBuffer));
this.notifyObserver();
}
・・・・
}
public class TokenManager
{
・・・・
//修正
public void setNewString(String parameterName, String str)
{
StringBuilder sb = new StringBuilder();
sb.append(str);
m_parsedData.newContext(parameterName, sb);
}
・・・・
}
コメント
コメントを投稿する
SpecialPR