第003回_マイルストーン、パーサの特徴・設計・解析手法
»
1回目/2回目は自己紹介や意図について書きました。
3回目から技術情報を書くと述べたので今回から読んでくださる方もいると思っています。
このコラムではまずXMLパーサを作成します。
1回目/2回目までに述べてきた構図を整理すると以下のようになります。
・最終結果のツリーはVisitorパターン用のインタフェースを持つ
・実装言語はJava
とします。
■パーサの立ち位置
パーサはどのようなプログラムかというと、形式言語を解析して動作するプログラムと言えます。プログラマが一番馴染みがある形式言語はプログラム言語そのものです。
■言語処理系
そして、プログラム言語を解析するプログラムは「人が理解できるプログラム言語で書かれたプログラムをコンピュータが理解できる機械語に変換するソフトウェア」と定義できます。このようなソフトウェアを言語処理系と呼びます。
■言語処理系の種類
言語処理系には大別してコンパイラ型とインタプリタ型があります。
■言語処理系の設計
言語処理系の設計について見ていきましょう。コンパイラは、ソースコードを字句解析・構文解析して中間コード/アセンブラ/バイナリを出力するパーサですから、コンパイラの設計をXMLパーサへ流用できます。そこで、コンパイラ型言語処理系パーサを作ることを検討します。
#補足
# コンパイラ型言語処理系パーサの反対の意味は
# インタプリタ型言語処理系パーサとします
#
1.字句解析(ファイルを読み込み、tokenに分解する)
2.構文解析(token列を抽象構文木に変換する)
3.意味解析(構文で評価できない制約について処理する)
のフェーズに分類できます。
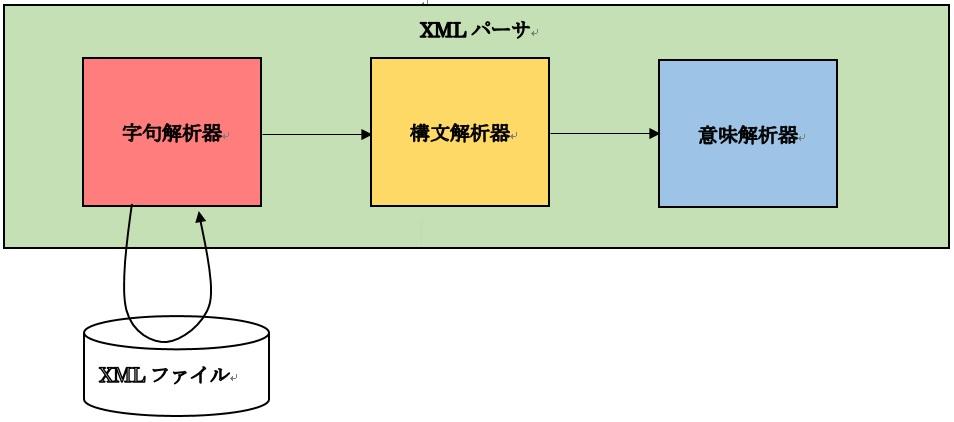
003-1.ソフトウェア構成図
※LL (1)とは、「入力文字列を左から構文解析していき、左端導出を行う。また左端導出のための先読みトークンは1」という意味です。
ここで「コンパイラ言語の言語処理系」のパーサならLR法で書くべきであると識者の方に言われるかもしれません。
LL法を採用する理由は
・LR法は手書きで書くのに向いていない
・作者の研究不足(こちらのウェイトのが大きい)
の2つがあり、本コラムではLL法を用います。
現在の予定では、
~15回くらいまで:字句解析と構文解析の連携構造の解説
~30回くらいまで:字句解析器の仕様整理と実装
~35回くらいまで:構文解析器の実装
~70回:意味解析の一部を検討・実装
となっています。このコラムは書籍化を目指している研究の原稿なので意味解析の途中までしか説明しません。
その後は、
ログ機構とプリプロセッサ
パーサの汎用化(パーサジェネレータ)
テストコードジェネレータ
について説明して合わせて90回くらいを予定しています。
他にも書きたい内容があるので書籍化しなければさらに続いて100回まで続く可能性があります。
3回目から技術情報を書くと述べたので今回から読んでくださる方もいると思っています。
このコラムではまずXMLパーサを作成します。
マイルストーン
XMLパーサを実装していく過程は非常に長くなるので中間目標(マイルストーン)を設けます。1回目/2回目までに述べてきた構図を整理すると以下のようになります。
| システムエンジニアの仕事環境を良くしたい |
| ->(パーサを使って)効率性を上げたい |
| ->パーサを自作できるようにしたい |
| ->汎用的なパーサを作りたい |
| ->汎用的なパーサはXMLの定義ファイルを読み込み定義ファイル に応じたパーサを生成する |
| ->XMLの定義ファイルを読み込む部分を自作することで作成したい 汎用的なパーサの土台とする |
■中間目標1
W3C勧告になるべく準拠した自作のXMLパーサ(XMLプロセッサ)を作成することを目標とします。ただし、面倒な仕様部分についてはW3C勧告の仕様から外れた実装をするかもしれません。
この自作XMLパーサの特徴は、Visitorパターンのインタフェースを持つこととします。
「なるべく」と書いたのは、サロゲートペアに関する処理を簡単に記述する方法がみつからなかった事が主な理由になります。何か良い参考書や参考になるサイトがありましたらご教示願います。
W3C勧告になるべく準拠した自作のXMLパーサ(XMLプロセッサ)を作成することを目標とします。ただし、面倒な仕様部分についてはW3C勧告の仕様から外れた実装をするかもしれません。
この自作XMLパーサの特徴は、Visitorパターンのインタフェースを持つこととします。
「なるべく」と書いたのは、サロゲートペアに関する処理を簡単に記述する方法がみつからなかった事が主な理由になります。何か良い参考書や参考になるサイトがありましたらご教示願います。
■中間目標2
後の説明で明らかになりますが、XMLの仕様は後方互換等を考慮したり、DTDのような古い考えに縛られた部分があります。そこで、そのような仕様を削除したXMLライクな独自マークアップ言語の仕様を規定し、それに合致するパーサを作成することを目標とします。この自作パーサは、前述のXMLパーサをベースに作成します。
後の説明で明らかになりますが、XMLの仕様は後方互換等を考慮したり、DTDのような古い考えに縛られた部分があります。そこで、そのような仕様を削除したXMLライクな独自マークアップ言語の仕様を規定し、それに合致するパーサを作成することを目標とします。この自作パーサは、前述のXMLパーサをベースに作成します。
■中間目標3
目標1で作ったXMLパーサと目標2の独自パーサを基本にして、パーサのコードジェネレータを作成します。
目標1で作ったXMLパーサと目標2の独自パーサを基本にして、パーサのコードジェネレータを作成します。
W3C勧告になるべく準拠した自作のXMLパーサの特徴
ということで、これから設計するパーサの特徴を簡潔に書くと以下のようになります。・最終結果のツリーはVisitorパターン用のインタフェースを持つ
・実装言語はJava
とします。
パーサの設計
パーサのソフトウェア構造をオリジナリティあふれるアイディアで作成しても良いのですが、古くから使われているものを流用するほうが安全で誰もが納得してくださると思います。■パーサの立ち位置
パーサはどのようなプログラムかというと、形式言語を解析して動作するプログラムと言えます。プログラマが一番馴染みがある形式言語はプログラム言語そのものです。
■言語処理系
そして、プログラム言語を解析するプログラムは「人が理解できるプログラム言語で書かれたプログラムをコンピュータが理解できる機械語に変換するソフトウェア」と定義できます。このようなソフトウェアを言語処理系と呼びます。
■言語処理系の種類
言語処理系には大別してコンパイラ型とインタプリタ型があります。
■言語処理系の設計
言語処理系の設計について見ていきましょう。コンパイラは、ソースコードを字句解析・構文解析して中間コード/アセンブラ/バイナリを出力するパーサですから、コンパイラの設計をXMLパーサへ流用できます。そこで、コンパイラ型言語処理系パーサを作ることを検討します。
#補足
# コンパイラ型言語処理系パーサの反対の意味は
# インタプリタ型言語処理系パーサとします
#
尚、XMLのパーサにとって最適かどうかは考慮しません。
コンパイラ言語の言語処理系は
1.字句解析(ファイルを読み込み、tokenに分解する)
2.構文解析(token列を抽象構文木に変換する)
3.意味解析(中間コードに変換する)
4.最適化(効率のよいコードに変換する)
5.コード生成(オブジェクトファイルを生成する)
のフェーズに分類できます。
ただし、最適化は速度の問題になるので今回は除外します。また、コード生成も不要です。
1.字句解析(ファイルを読み込み、tokenに分解する)
2.構文解析(token列を抽象構文木に変換する)
3.意味解析(構文で評価できない制約について処理する)
のフェーズに分類できます。

解析手法について
今回は、LL (1)で解析します。※LL (1)とは、「入力文字列を左から構文解析していき、左端導出を行う。また左端導出のための先読みトークンは1」という意味です。
ここで「コンパイラ言語の言語処理系」のパーサならLR法で書くべきであると識者の方に言われるかもしれません。
LL法を採用する理由は
・LR法は手書きで書くのに向いていない
・作者の研究不足(こちらのウェイトのが大きい)
の2つがあり、本コラムではLL法を用います。
その他
タイトルに第XXX回とあるので、このコラムが100回続くの?という声をいただきました。ありがとうございます。現在の予定では、
~15回くらいまで:字句解析と構文解析の連携構造の解説
~30回くらいまで:字句解析器の仕様整理と実装
~35回くらいまで:構文解析器の実装
~70回:意味解析の一部を検討・実装
となっています。このコラムは書籍化を目指している研究の原稿なので意味解析の途中までしか説明しません。
その後は、
ログ機構とプリプロセッサ
パーサの汎用化(パーサジェネレータ)
テストコードジェネレータ
について説明して合わせて90回くらいを予定しています。
他にも書きたい内容があるので書籍化しなければさらに続いて100回まで続く可能性があります。
コメント
コメントを投稿する
SpecialPR