第021回_TokenManagerの実装3_コンテキスト切り替え機能
»
TokenManagerの基本的な機能については紹介が終わりましたので、最後にコンテキスト(文脈)の切り替え機能を実装します。
ただ、この機能の必要性がわかり難いのでまずは処理中のコンテキストが切り替わるという話から説明していきます。
一方、なんらかの操作・事由によって(バッファやFIFO、消費カウンタをリセットしたり別の領域に退避するような)非連続的に変化する場合、コンテキストが切り替わると呼ぶことにします。
1. 宣言間のパラメータ実体を展開するとき
2. 実体値リテラル内のパラメータ実体を展開するとき
3. 外部サブセットを読み込むとき
コンテキストが切り替わります。
この3つ以外にもコンテキストが切り替わるタイミングがありますが、W3Cの勧告をしっかりと読まないと理解が難しいので今回は説明しません。
上記の3つの場合について検討した上で、基本的なコンテキストを切り替える機能について検討します。
「2.8 プロローグと文書型宣言」
extSubsetDecl ::= ( markupdecl | conditionalSect | DeclSep)*
にマッチします。パラメータ実体の置換文字列はDeclSepが所属する場所に入れ替えてintSubsetの一部として解析するのではなく、独立したextSubsetDeclとして処理するとなります。
このことは「もしextSubsetDeclの中のDeclSepでさらにパラメータ実体が現れた場合、その置換文字列もextSubsetDeclで解析する」ということも示しており、パラメータ実体の処理は再帰的に行う必要があります。
■置換文字列を構文解析するときに行うこと
「4.4.5 リテラルの中でインクルードされる」
ReplacementText ::= ([^%&] | PEReference | Reference)*
にマッチします。パラメータ実体の置換文字列はPEReferenceが所属する場所に入れ替えてEntityValueの一部として解析するのではなく、独立したReplacementTextとして処理するとなります。
このことは「もしReplacementTextの中のPEReferenceでさらにパラメータ実体が現れた場合、その置換文字列もReplacementTextで解析する」ということも示しており、パラメータ実体の処理は再帰的に行う必要があります。
■置換文字列を構文解析するときに行うこと
「2.8 プロローグと文書型宣言」
extSubset ::= TextDecl? extSubsetDecl
にマッチします。外部サブセットの内容は異なるファイルの内容なのでTokenManagerが現在保持しているDocumentTokenを退避して、外部サブセットのDocumentTokenを受け入れます。
■extSubsetを構文解析するときに行うこと
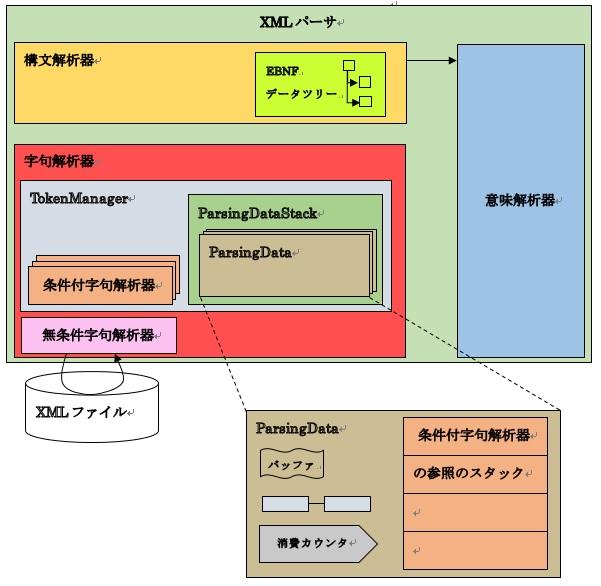
しかし、これまでの検討からわかるようにTokenManagerは多くの機能を持つ上に、構文解析からのアクセスを受ける唯一のクラスですから、内部的な操作が複雑になるとTokenManagerのクラスが複雑になりすぎます。
そこで、構文解析中のデータをTokenManagerから分離します。また、構文解析中データをコンテキスト切り替え可能にするためスタック化します。
これらを合わせて、ParsingDataStackクラスを用意してTokenManagerにcomposite構造として持たせます。ParsingDataStackクラスはParsingDataクラスをスタックとして管理することにします。
ParsingDataStackクラスは、条件付字句解析の各クラスとTokenManagerから呼び出す必要があるためシングルトンで用意します。
021-1.ソフトウェア構成図
■字句解析器の切り替え時の処理
字句解析器の切り替え時にトークンリスト内に残った消費されていないトークン と 未完成のトークンをリセットします。
■機能要件
と定義することができます。
■実装
■機能要件
と定義することができます。
■実装
ParsingDataStackを使ってTokenManagerを整理します。
■実装
ただ、この機能の必要性がわかり難いのでまずは処理中のコンテキストが切り替わるという話から説明していきます。
コンテキスト(用語の定義)
字句解析器/構文解析器はファイルを先頭から終りに向けて順に読み込みます。これを本コラムではコンテキスト(文脈)と呼ぶことにします。また、読み込むのに同期してTokenManagerが保持するバッファ・FIFO・消費カウンタが変化しますから、これらがある時点Xからある時点Yまで連続的に変化する(または変化しない)場合、同一のコンテキストと呼ぶことにします。一方、なんらかの操作・事由によって(バッファやFIFO、消費カウンタをリセットしたり別の領域に退避するような)非連続的に変化する場合、コンテキストが切り替わると呼ぶことにします。
代表的なコンテキストが切り替わる構文
次の3つの場合。1. 宣言間のパラメータ実体を展開するとき
2. 実体値リテラル内のパラメータ実体を展開するとき
3. 外部サブセットを読み込むとき
コンテキストが切り替わります。
この3つ以外にもコンテキストが切り替わるタイミングがありますが、W3Cの勧告をしっかりと読まないと理解が難しいので今回は説明しません。
上記の3つの場合について検討した上で、基本的なコンテキストを切り替える機能について検討します。
1.宣言間のパラメータ実体を展開するとき
宣言間のパラメータ実体に関する仕様についてW3C勧告を確認します。「2.8 プロローグと文書型宣言」
----W3C勧告----
Well-formedness constraint: PE Between Declarations
The replacement text of a parameter entity reference in a DeclSep must match the production extSubsetDecl.
----W3C勧告----The replacement text of a parameter entity reference in a DeclSep must match the production extSubsetDecl.
----日本語訳----
とあり、置換文字列は
整形式性制約: 宣言の間のパラメータ実体
DeclSepの中のパラメータ実体の参照が指す置換文字列は、extSubsetDeclの生成規則にマッチしなければならない。
----日本語訳----DeclSepの中のパラメータ実体の参照が指す置換文字列は、extSubsetDeclの生成規則にマッチしなければならない。
extSubsetDecl ::= ( markupdecl | conditionalSect | DeclSep)*
にマッチします。パラメータ実体の置換文字列はDeclSepが所属する場所に入れ替えてintSubsetの一部として解析するのではなく、独立したextSubsetDeclとして処理するとなります。
このことは「もしextSubsetDeclの中のDeclSepでさらにパラメータ実体が現れた場合、その置換文字列もextSubsetDeclで解析する」ということも示しており、パラメータ実体の処理は再帰的に行う必要があります。
■置換文字列を構文解析するときに行うこと
置換文字列に対して、新たにextSubsetDeclを適用するためには、TokenManagerの
に変更する必要があるのでコンテキストが切り替わります。
| トークンバッファ | : | PEReferenceが指すパラメータ実体の参照(置換文字列) |
| トークンリスト | : | 新規のリスト |
| 消費カウンタ | : | 新規のカウンタ |
| 字句解析器のスタック | : | 新規のスタック(初期スタックはNormalSection) |
2.実体値リテラル内のパラメータ実体を展開するとき
実体値リテラル内のパラメータ実体に関する仕様についてW3C勧告を確認します。「4.4.5 リテラルの中でインクルードされる」
----W3C勧告----
When an entity reference appears in an attribute value, or a parameter entity reference appears in a literal entity value, its replacement text must be processed in place of the reference itself as though it were part of the document at the location the reference was recognized, except that a single or double quote character in the replacement text must always be treated as a normal data character and must not terminate the literal. For example, this is well-formed:
----W3C勧告--------日本語訳----
とあり、対象文字列は引用符を除いたEntityValueの構文
AttValueの中の実体参照が現れる場合、もしくはEntityValueの中でパラメータ実体の参照が現れる場合、文書内で、その参照を認識した場所でその参照文字列があったように処理しなければならない。ただし、置換文字列の中の単引用符文字・二重引用符文字は例外として、単なる文字として扱わなければならず、もし単引用符・二重引用符がでてきてもリテラルを終了してはいけない。次の例は整形式である。
----日本語訳----ReplacementText ::= ([^%&] | PEReference | Reference)*
にマッチします。パラメータ実体の置換文字列はPEReferenceが所属する場所に入れ替えてEntityValueの一部として解析するのではなく、独立したReplacementTextとして処理するとなります。
このことは「もしReplacementTextの中のPEReferenceでさらにパラメータ実体が現れた場合、その置換文字列もReplacementTextで解析する」ということも示しており、パラメータ実体の処理は再帰的に行う必要があります。
■置換文字列を構文解析するときに行うこと
置換文字列に対して、新たにReplacementTextを適用するためには、TokenManagerの
に変更する必要があるのでコンテキストが切り替わります。
| トークンバッファ | : | PEReferenceが指すパラメータ実体の参照(置換文字列) |
| トークンリスト | : | 新規のリスト |
| 消費カウンタ | : | 新規のカウンタ |
| 字句解析器のスタック | : | 新規のスタック(初期スタックはNormalSection) |
3.外部サブセットを読み込むとき
外部サブセットに関する仕様についてW3C勧告を確認します。「2.8 プロローグと文書型宣言」
----W3C勧告----
Well-formedness constraint: External Subset
The external subset, if any, must match the production for extSubset
----W3C勧告----The external subset, if any, must match the production for extSubset
----日本語訳----
とあり、外部ファイルの内容は
整形式性制約: 外部サブセット
外部サブセットがもしあるなら、外部サブセットはextSubsetの生成規則にマッチしなければならない。
----日本語訳----外部サブセットがもしあるなら、外部サブセットはextSubsetの生成規則にマッチしなければならない。
extSubset ::= TextDecl? extSubsetDecl
にマッチします。外部サブセットの内容は異なるファイルの内容なのでTokenManagerが現在保持しているDocumentTokenを退避して、外部サブセットのDocumentTokenを受け入れます。
■extSubsetを構文解析するときに行うこと
外部サブセットの内容に対して、新たにextSubsetを適用するためには、TokenManagerの
に変更する必要があるのでコンテキストが切り替わります。
| トークンバッファ | : | ExternalIDの示すURIが参照するデータの中身 |
| トークンリスト | : | 新規のリスト |
| 消費カウンタ | : | 新規のカウンタ |
| 字句解析器のスタック | : | 新規のスタック(初期スタックはNormalSection) |
コンテキストを切り替える機能の設計
斯くの如く、コンテキストが切り替わるときに構文解析中のデータ(TokenManagerのフィールド)を操作する必要があります。しかし、これまでの検討からわかるようにTokenManagerは多くの機能を持つ上に、構文解析からのアクセスを受ける唯一のクラスですから、内部的な操作が複雑になるとTokenManagerのクラスが複雑になりすぎます。
そこで、構文解析中のデータをTokenManagerから分離します。また、構文解析中データをコンテキスト切り替え可能にするためスタック化します。
これらを合わせて、ParsingDataStackクラスを用意してTokenManagerにcomposite構造として持たせます。ParsingDataStackクラスはParsingDataクラスをスタックとして管理することにします。
ParsingDataStackクラスは、条件付字句解析の各クラスとTokenManagerから呼び出す必要があるためシングルトンで用意します。

ParsingData
ParsingDataクラスはある文脈で必要な解析中のデータの集合です。■字句解析器の切り替え時の処理
字句解析器の切り替え時にトークンリスト内に残った消費されていないトークン と 未完成のトークンをリセットします。
■機能要件
| 1. | 解析中データ(バッファ、トークンリスト、消費カウンタ、字句解析器スタック)を持つ |
| 2. | バッファを取得する機能 |
| 3. | トークンリストを取得する機能 |
| 4. | トークンを消費する機能 |
| 5. | 消費カウンタを取得する機能 |
| 6. | 消費カウンタをインクリメントする機能 |
| 7. | 字句解析器スタックを取得する機能 |
| 8. | セクションの開始機能(新しい字句解析器に移るので、旧字句解析器が作成したトークンをリストから取り除く) |
| 9. | セクションの終了機能(古い字句解析器に戻るので、今の字句解析器が作成したトークンをリストから取り除く) |
■実装
public class ParsingData
{
//トークンバッファ
private StringBuilder m_str;
//トークンリスト
private LinkedList<Token> m_list;
//消費カウンタ
protected Integer m_consumedCounter;
//字句解析器のスタック
protected BaseStackLexer m_stack;
public ParsingData(StringBuilder newBuffer)
{
m_str = newBuffer;
m_list = new LinkedList<Token>();
m_consumedCounter = new Integer(0);
m_stack = new BaseStackLexer();
}
public StringBuilder getStringBuilder()
{
return m_str;
}
public LinkedList<Token> getList()
{
return m_list;
}
public int getConsumeCounter()
{
return m_consumedCounter;
}
public void consume()
{
Token token = m_list.poll();
int len = token.length();
m_str.delete(0, len);
m_consumedCounter++;
}
public BaseStackLexer getStackLexer()
{
return m_stack;
}
public void startSection()
{
clear();
}
public void endSection()
{
m_stack.pop();
clear();
}
private void clear()
{
//リストが空でない場合
if (!m_list.isEmpty())
{
m_tokenBuilder.clear();
m_list.clear();
}
}
}
ParsingDataStack
ParsingDataStackクラスはTokenManagerが構文解析全体で必要とする文脈で利用する解析中データの集合とその操作を司ります。■機能要件
| 1. | ParsingDataをStackとして持つ |
| 2. | シングルトン機能 |
| 3. | 新しいコンテキストを作成し、そこに移動する(新しいParsingDataをスタックに積む)機能 |
| 4. | 前のコンテキストに戻る(スタックからParsingDataをポップする)機能 |
| 5. | ParsingDataの機能のラッパーメソッド |
■実装
public class ParsingDataStack
{
private static ParsingDataStack m_instance = new ParsingDataStack();
private Stack<ParsingData> m_data;
private ParsingDataStack()
{
m_data = new Stack<ParsingData>();
}
public static ParsingDataStack getInstance()
{
return m_instance;
}
//新しいコンテキストを作って、そこに移動する
public void newContext(StringBuilder newBuffer)
{
m_data.push(new ParsingData(newBuffer));
}
//1つ前のコンテキストに戻る
public void goBackPreviousContext()
{
m_data.pop();
}
public StringBuilder getStringBuilder()
{
ParsingData pd = m_data.peek();
return pd.getStringBuilder();
}
public LinkedList<Token> getList()
{
ParsingData pd = m_data.peek();
return pd.getList();
}
public int getConsumeCounter()
{
ParsingData pd = m_data.peek();
return pd.getConsumeCounter();
}
public void consume()
{
ParsingData pd = m_data.peek();
pd.consume();
}
public BaseStackLexer getStackLexer()
{
ParsingData pd = m_data.peek();
return pd.getStackLexer();
}
public void startSection()
{
ParsingData pd = m_data.peek();
pd.startSection();
}
public void endSection()
{
ParsingData pd = m_data.peek();
pd.endSection();
}
}
TokenManagerの修正
■修正内容ParsingDataStackを使ってTokenManagerを整理します。
| 1. | これまでの各解析中データを削除し、解析中データのスタックとなるm_parsedDataを持つ |
| 2. | これまでの各解析中データをm_parsedDataから取得するように修正する |
| 3. | コンテキストを切り替えるメソッドsetNewStringを追加する |
| 4. | コンテキストを前の状態に戻すメソッドfinalizeを追加する |
public class TokenManager
{
private static final TokenManager m_instance = new TokenManager();
//追加
private static ParsingDataStack m_parsedData = ParsingDataStack.getInstance();
//シングルトンパターン
private TokenManager(){}
public static TokenManager getInstance()
{
return m_instance;
}
//修正
public void setDocumentToken(DocumentToken t)
{
//修正
//文字列バッファに設定する
StringBuilder str = new StringBuilder();
str.append(t.getStr());
//追加
m_parsingData.init(str);
}
//追加
public void setNewString(String str)
{
StringBuilder sb = new StringBuilder();
sb.append(str);
m_parsingData.newContext(sb);
}
//追加
public void finalize()
{
m_parsingData.goBackPreviousContext();
}
//修正
public void consumeToken()
{
m_parsingData.consumeToken();
}
//修正
public int getConsumedCount()
{
return m_parsingData.getConsumeCounter();
}
//修正
public Token nextToken()
{
LinkedList<Token> list = m_parsingData.getList();
//トークンリストが空の場合
if (list.isEmpty())
{
//追加で解析してlistを補充する
tokenize();
}
//トークンリストの先頭の参照を得る
Token token = list.getFirst();
return token;
}
//修正
//追加で解析してlistを補充する
private Token tokenize()
{
ConditionLexer lexer = m_parsingData.getStackLexer().peek();
StringBuilder str = m_parsingData.getStringBuilder();
Token token = lexer.nextToken(str);
LinkedList<Token> list = m_parsingData.getList();
list.add(token);
return token;
}
//修正
//字句解析器制御メソッド
public void notifyQuoteStart()
{
m_parsingData.getStackLexer().pushQuoteStart();
m_parsingData.startSection();
}
public void notifyQuoteEnd()
{
m_parsingData.endSection();
}
public void notifyDoubleQuoteStart()
{
m_parsingData.getStackLexer().pushDoubleQuoteStart();
m_parsingData.startSection();
}
public void notifyDoubleQuoteEnd()
{
m_parsingData.endSection();
}
public void notifyAttValueQuoteSectionStart()
{
m_parsingData.getStackLexer().pushAttValueQuoteSection();
m_parsingData.startSection();
}
public void notifyAttValueQuoteSectionEnd()
{
m_parsingData.endSection();
}
public void notifyAttValueDoubleQuoteSectionStart()
{
m_parsingData.getStackLexer().pushAttValueDoubleQuoteSection();
m_parsingData.startSection();
}
public void notifyAttValueDoubleQuoteSectionEnd()
{
m_parsingData.endSection();
}
public void notifyEntityValueQuoteSectionStart()
{
m_parsingData.getStackLexer().pushGeEntityValueQuoteSection();
m_parsingData.startSection();
}
public void notifyEntityValueQuoteSectionEnd()
{
m_parsingData.endSection();
}
public void notifyEntityValueDoubleQuoteSectionStart()
{
m_parsingData.getStackLexer().pushGeEntityValueDoubleQuoteSection();
m_parsingData.startSection();
}
public void notifyEntityValueDoubleQuoteSectionEnd()
{
m_parsingData.endSection();
}
public void notifyNormalSectionStart()
{
m_parsingData.getStackLexer().pushNormal();
m_parsingData.startSection();
}
public void notifyNormalSectionEnd()
{
m_parsingData.endSection();
}
public void notifyCDataStart()
{
m_parsingData.getStackLexer().pushCData();
m_parsingData.startSection();
}
public void notifyCDataEnd()
{
m_parsingData.endSection();
}
public void notifyCharDataStart()
{
m_parsingData.getStackLexer().pushCharData();
m_parsingData.startSection();
}
public void notifyCharDataEnd()
{
m_parsingData.endSection();
}
public void notifyIgnoreWordStart()
{
m_parsingData.getStackLexer().pushIgnore();
m_parsingData.startSection();
}
public void notifyIgnoreWordEnd()
{
m_parsingData.endSection();
}
public void notifyPIWordStart()
{
m_parsingData.getStackLexer().pushPI();
m_parsingData.startSection();
}
public void notifyPIWordEnd()
{
m_parsingData.endSection();
}
}
コメント
コメントを投稿する
SpecialPR