第019回_TokenManagerの実装1
»
今回はVisitorからトークンリストの生成機能(役割)を分離します。
TokenManager
以前に述べたSample1~4の実装例は字句解析が本来生成するトークン列をVisitorが直に持っています。これでは実際のXMLを読み込むことはできません。また、トークンリストを生成する機能をVisitorに含めると、Visitorが持つ「巡回する際の処理」という意味合いを大きく外れてしまいます。そこでVisitorの代わりにトークンリストを管理するクラス「TokenManager」を検討します。位置付け
TokenManagerクラスは必要があればトークンを生成し、トークンリストに追加します。よってソフトウェア構成において字句解析器に属します。構文解析器が字句解析器に対して要求することがトークンの取得であることから、TokenManagerは構文解析器がアクセスする唯一の字句解析クラス(窓口)としておくことでクラス構成を簡潔にできます。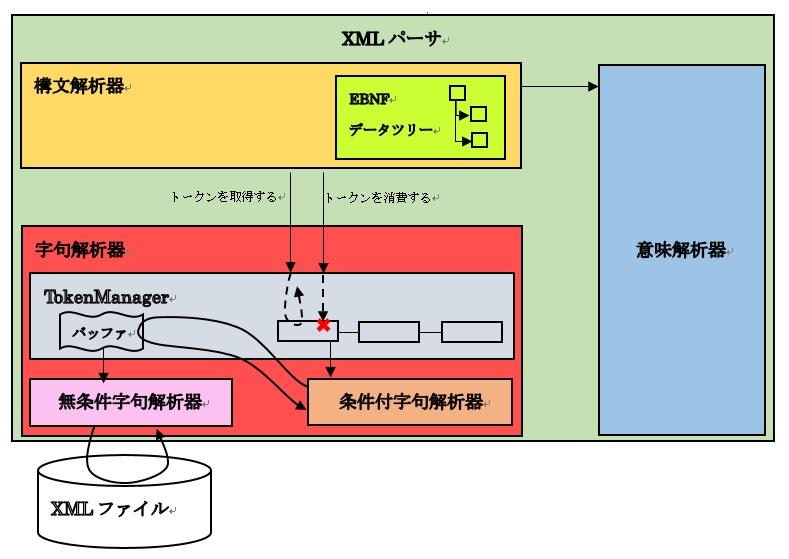
機能要件
TokenManagerに必要な機能は以下の5個です。1.無条件字句解析器が作成したDocumentTokenを保持する機能
2.(VisitorからのnextToken呼び出しで)次のtokenを適切な粒度で取得する機能
この機能は、条件付字句解析器を内部で呼び出します。(後述)
3.Visitorからの指示を起点に取得したtokenを消費する機能
この機能を実行するメソッドをconsumeTokenと命名します。
4.条件付字句解析を適切に呼び出す機能
5.コンテキスト切り替え機能
全体のクラス設計に関して簡単に説明した後に上記5つの機能を順に検討します。
0.クラス設計に関する機能
TokenManagerは、字句解析処理中に唯一つあれば十分です。よってシングルトンパターンで設計します。
public class TokenManager
{
private static final TokenManager m_instance = new TokenManager();
//シングルトンパターン
private TokenManager()
{
}
public static TokenManager getInstance()
{
return m_instance;
}
}
1.無条件字句解析器が取得したDocumentTokenを保持する機能
TokenManager#setDocumentTokenメソッドを用意します。Lexer(無条件字句解析器)から呼び出して対象となる文字列バッファをフィールド変数に保持します。
public class TokenManager
{
・・・
//追加:文字列バッファ
private StringBuilder m_str;
・・・
//追加
public void setDocumentToken(DocumentToken t)
{
//文字列バッファに設定する
m_str = new StringBuilder();
m_str.append(t.getStr());
}
}
2.次のtokenを適切な粒度で取得する機能
TokenManager#nextTokenメソッドを用意します。このメソッドは、Sample1~4のnextToken()と同じタイミングで呼び出します。
つまり、TokenManager#nextTokenは以下の機能が必要です。
1.トークンの消費指示がない限り同じトークンを取り出す
2.トークンの消費指示があると次のトークンを取り出す
尚、トークンの消費指示とは後述する3番の機能:consumeTokenのことです。
上記の機能を実現するためには2つの方法があります。
■1.トークンリスト(FIFO)を用意する方法
1.nextToken()呼び出し時にトークンバッファからトークンを生成してFIFOに追加します。
※ただし、consumeToken()が呼ばれるまでトークンバッファを変更しません。
2.consumeToken()を呼び出す前で、かつ、FIFOが空でない場合、次のnextToken()を呼び出した時は単にFIFO内の同じトークンを返します。
3.consumeToken()呼び出し時にFIFOの先頭トークンを消費します。同時に、先頭トークンと同じ文字数分、トークンバッファからも削除します。
4.条件付字句解析の条件が変更になった場合、nextToken()の取り出し内容が変わるかもしれないのでFIFOの中身を空にします。
4-1.メリット
実装は次のようにします。
ただし、tokenize()部分は次回説明する字句解析器を使ってトークンを取得するため今回は実装しません。
1.nextToken()呼び出し時にトークンリストが空の場合
トークンを生成し、トークン分だけトークンバッファを削除し、
生成したトークンはトークンリストに追加する
生成したトークンを呼び出し元に返す
2.nextToken()呼び出し時にトークンリストが空でない場合
トークンリストから1つのトークンを取り出す(トークン自体は消えない)
3.consumeToken()呼び出し時にトークンリストの先頭を削除する
1-1.メリット
■2.トークンバッファを直接操作する方法トークンを生成し、トークン分だけトークンバッファを削除し、
生成したトークンはトークンリストに追加する
生成したトークンを呼び出し元に返す
2.nextToken()呼び出し時にトークンリストが空でない場合
トークンリストから1つのトークンを取り出す(トークン自体は消えない)
3.consumeToken()呼び出し時にトークンリストの先頭を削除する
1-1.メリット
何度もnextToken()を呼び出す場合に生成コストが少なくて済みます。尚、このメリットは構文に 試行規則(|,*,?のように一致しなくてもエラーにならない規則)が多くても解析時間への影響が少なくて済みます。
1-2.デメリット
条件付字句解析は取りうる全ての解析ができなくてはいけません。
例えば、
element ::= SYMBOL ('<') Name (S Attribute)* S? ( SYMBOL ('/>') | ( SYMBOL ('>') content ETag) )
content ::= CharData? ((element | Reference | CDSect | PI | Comment) CharData?)*
のcontentの先頭で1つのトークンを取得する場合、
1.CharDataトークンを取る可能性
2.elementの先頭のSYMBOL('<')を取る可能性
3.Referenceの先頭のSYMBOL ('&'),SYMBOL ('&#').SYMBOL ('&#x')を取る可能性
4.CDSectの先頭のSYMBOL('<![CDATA[')を取る可能性
5.PIの先頭のSYMBOL('<?')を取る可能性
6.COMMENTトークンを取る可能性
7.contentが空でETagの先頭のSYMBOL('</')を取る可能性
があります。
上記の検討はCHARDATA_WORDを単に取り出すトークナイザ(トークン生成器)よりずっと複雑な実装になります。
例えば、
element ::= SYMBOL ('<') Name (S Attribute)* S? ( SYMBOL ('/>') | ( SYMBOL ('>') content ETag) )
content ::= CharData? ((element | Reference | CDSect | PI | Comment) CharData?)*
のcontentの先頭で1つのトークンを取得する場合、
1.CharDataトークンを取る可能性
2.elementの先頭のSYMBOL('<')を取る可能性
3.Referenceの先頭のSYMBOL ('&'),SYMBOL ('&#').SYMBOL ('&#x')を取る可能性
4.CDSectの先頭のSYMBOL('<![CDATA[')を取る可能性
5.PIの先頭のSYMBOL('<?')を取る可能性
6.COMMENTトークンを取る可能性
7.contentが空でETagの先頭のSYMBOL('</')を取る可能性
があります。
上記の検討はCHARDATA_WORDを単に取り出すトークナイザ(トークン生成器)よりずっと複雑な実装になります。
1.nextToken()呼び出し時にトークンバッファからトークンを生成します。
※ただし、consumeToken()が呼ばれるまでトークンバッファを変更しません。
2.consumeToken()を呼び出さずに再度nextToken()を呼び出した場合は同じトークンを生成します。
3.consumeToken()呼び出し時にトークンバッファから消費したトークン分のバッファを削除します。
2-1.メリット
■3.案1と案2の検討※ただし、consumeToken()が呼ばれるまでトークンバッファを変更しません。
2.consumeToken()を呼び出さずに再度nextToken()を呼び出した場合は同じトークンを生成します。
3.consumeToken()呼び出し時にトークンバッファから消費したトークン分のバッファを削除します。
2-1.メリット
トークンの生成を何度も行うため、条件付字句解析は取りうる全ての解析ができる必要がありません。構文によっては間違ったトークンを生成してしまっても良いです。
2-2.デメリット
nextToken()を呼び出す毎に生成コストが必要なため、consumeToken()を呼び出さない場合(試行規則が多い場合)生成コストが多くなります。また、構文の適用順序によっては、間違ったトークンを生成したまま処理が終了する場合があります。このとき、エラー文言に表示するトークンはユーザの認識とずれてしまうことがあり得ます。
XMLの条件付字句解析器においてContentspecの区間やAttValueの区間のためのトークンを取得する部分は複雑になります。そこで、字句解析器の実装が難しくなることを避けるために基本構造は案1を選択します。ただし、トークン生成コストを最小限にするため案2とのハイブリット案3(以下に説明)について考えて見ます。
■4.FIFOを使いつつ、トークンバッファからの削除処理はconsumeToken()時にする方法1.nextToken()呼び出し時にトークンバッファからトークンを生成してFIFOに追加します。
※ただし、consumeToken()が呼ばれるまでトークンバッファを変更しません。
2.consumeToken()を呼び出す前で、かつ、FIFOが空でない場合、次のnextToken()を呼び出した時は単にFIFO内の同じトークンを返します。
3.consumeToken()呼び出し時にFIFOの先頭トークンを消費します。同時に、先頭トークンと同じ文字数分、トークンバッファからも削除します。
4.条件付字句解析の条件が変更になった場合、nextToken()の取り出し内容が変わるかもしれないのでFIFOの中身を空にします。
4-1.メリット
条件付字句解析の条件が変わらない限り、何度もnextToken()を呼び出す場合に生成コストが少なくて済みます。条件付字句解析は取りうる全ての解析ができなくても良く、構文によっては間違ったトークンを生成してしまっても良くなります。
4-2.デメリット
構文の適用順序によっては、間違ったトークンを生成したまま処理が終了する場合があります。このとき、エラー文言に表示するトークンはユーザの認識とずれてしまうことがあり得ます。
■5.実装実装は次のようにします。
ただし、tokenize()部分は次回説明する字句解析器を使ってトークンを取得するため今回は実装しません。
public class TokenManager
{
private static final TokenManager m_instance = new TokenManager();
private StringBuilder m_str;
//追加
private LinkedList<Token> m_list;
private TokenManager()
{
//追加
m_list = new LinkedList<Token>();
}
・・・・・
//追加
public Token nextToken()
{
//トークンリストが空の場合
if (m_list.isEmpty())
{
//追加で解析してlistに追加する
//この処理を実行してもトークンバッファは不変である
this.tokenize();
}
//トークンリストの先頭を取得する(削除はしない)
Token token = m_list.getFirst();
//トークンを返す
return token;
}
}
3.Visitorからの指示を起点に取得したtokenを消費する機能
consumToken()メソッドを追加します。内容については、先ほどの案3に沿って実装します。また、RepetitionやAlternativeでNG判定をするためにトークンの消費数をカウントする機能が必要になります。
public class TokenManager
{
//消費カウンタ
private int m_consumedCounter;
・・・・
private TokenManager()
{
・・・・
m_consumedCounter = 0;
}
・・・・
//追加
public void consumeToken()
{
//先頭のトークンをリストから削除する
Token token = m_list.poll();
//削除するトークンのサイズを取得する
int len = token.length();
//実際にトークンバッファの先頭から
//トークン分の文字列を削除する
m_str.delete(0, len);
//消費カウンタを+1する
m_consumedCounter++;
}
//追加
public int getConsumedCounter()
{
return m_consumedCounter;
}
}
コメント
コメントを投稿する
SpecialPR