第011回_構文解析Sample1および2
»
今回は、
新説Visitorパターンの補足
Sample共通処理と共通のクラス
Sample1:単項の構文解析
Sample2:連接の構文解析
を説明します。
新説Visitorパターンの補足は前回投稿の時点で気づいていたのですが、回を分けた方が納得感が出ると思ったので今回書かせていただきます。
補足といっても重要な内容なので、0/1相転移炉によるVisitorパターンの整理と定義しておきます。
■ノードを巡回する順番を決めるのは、訪問者か受け入れか?
-Acceptor/巡回する方法の種類
■共通処理1.トークンリストの作成
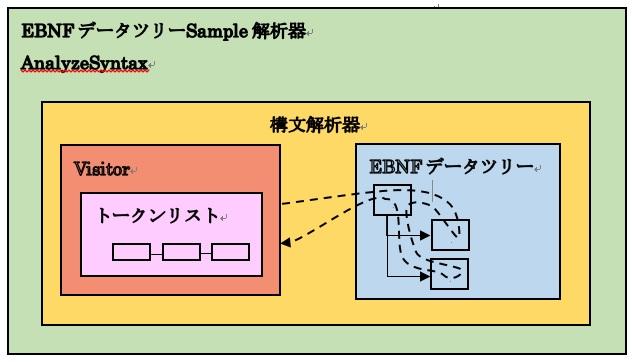
011-1.ソフトウェア構成図
■共通クラス EbnfNodeAcceptor
構文は、
EBNFデータツリー:LITERAL ('1.1')
とし、これに対し、
入力トークンリスト:LITERAL ('1.1')
を解析する処理を考えてみます。
共通の処理で説明した内容に加えて、
Sample1Visitor::visit(EbnfLimitedLiteralNode n)
では、トークンの種別をチェックしたあと、内容が一致するか判定します。
■Sample1のAnalyzeSyntax
■LimitedLiteralNode
■Sample1Visitor
Sample1を実行するとプログラムはコンソールにtrueを表示します。もし、 Sample1Visitorのコンストラクタを他の文字列にすればfalseを表示しますから、これによってLITERALの単項をチェックすることができるようになります。今回は、LITERALトークンを解析しましたが、SYMBOLなどのその他のトークンの処理の仕方も同じように実装できます。
Sequence構文の確認する内容は、「全ての子ノードを順に処理する」ことです。
より詳細に説明すれば、
子ノードの構文の処理結果を確認する
処理結果がOKの場合は、次の子ノード処理へ
処理結果がNGの場合は、次の子ノード処理へ行かずにSequenceの結果もNGとする
となります。
構文は、
EBNFデータツリー:
seq(Sequence)
├+WORD ('version')
├+SYMBOL ('=')
└+LITERAL ('1.1')
とし、これに対し、
入力トークンリスト:WORD ('version') SYMBOL ('=') LITERAL ('1.1')
を解析する処理を考えてみます。
共通の処理で説明した内容に加えて、
Sample1Visitor::visit(EbnfSequenceNode n)
では、先ほど述べたSequence構文の処理を実装します。また、
Sample2Visitor::visit(EbnfSymbolNode n)
Sample2Visitor::visit(EbnfLimitedWordNode n)
の中でトークンの種別をチェックしたあと内容が一致するか判定します。
■Sample2のanalyzeSyntax
■EbnfSequenceNode
■EbnfLimitedWordNode
■EbnfSymbolNode
■Sample2Visitor
これで連接をチェックすることができました。
新説Visitorパターンの補足
Sample共通処理と共通のクラス
Sample1:単項の構文解析
Sample2:連接の構文解析
を説明します。
新説Visitorパターンの補足は前回投稿の時点で気づいていたのですが、回を分けた方が納得感が出ると思ったので今回書かせていただきます。
補足といっても重要な内容なので、0/1相転移炉によるVisitorパターンの整理と定義しておきます。
0/1相転移炉によるVisitorパターンの整理(新説Visitorパターンの補足)
補足するべき箇所は、
■訪問者(Visitor)側の役割
ノードを巡回すること
解析動作を行うこと
■受け入れ(Acceptor)側の役割
EBNFデータツリーの各ノード(非終端記号や終端記号)を表現すること
の部分です。ノードを巡回すること
解析動作を行うこと
■受け入れ(Acceptor)側の役割
EBNFデータツリーの各ノード(非終端記号や終端記号)を表現すること
■ノードを巡回する順番を決めるのは、訪問者か受け入れか?
Visitorパターンとしてはどちらも正しい実装です。どちらにするかで利点・欠点があり、利用者のためにそれらは次のように名称が付けてあります。
受け入れ側にすると巡回方法を固定することになり、拡張性が著しく下がってしまいます。そのため訪問者側で巡回するのが良いことが判ります。
ただし、単純にExternal Visitorを実装すると巡回方法が混乱しますから、次のように4つの役割毎のクラスを用意します。
上記のように役割分担することで扱い勝手の良い書き方ができるようになります。
具体性がないのでXMLパーサの実装を題材にクラスの種類を書いておきます| ノードを巡回する順番 | Visitorの種類 | 欠点・利点 |
| 受け入れが決める場合 | Internal Visitor | データ構造を公開しなくて良いが、巡回方法は固定になる |
| 訪問者が決める場合 | External Visitor | データ構造を公開する必要があるが、巡回方法は柔軟に定義できる |
ただし、単純にExternal Visitorを実装すると巡回方法が混乱しますから、次のように4つの役割毎のクラスを用意します。
| クラス | 役割/実装 |
| Acceptor/巡回する方法の種類 | Visitor側と連携して巡回動作を決定する |
| Acceptor/処理毎の種類 | Visitor側と連携して処理を決定する。Acceptor/巡回する方法の種類を継承することで巡回方法を決定する |
| Visitor/巡回処理 | Acceptor/巡回する方法の種類に対して巡回処理を定義する |
| Visitor/一連の処理 | Visitor/巡回処理を継承することで巡回方法を記載せずに処理だけを書く |
-Acceptor/巡回する方法の種類
Sequence、Alternative、Repetitionを表すクラスが相当します。
-Acceptor/処理毎の種類
documentやelementといった構文を表すクラスが相当します。
これらのクラスは内部的にSequence、Alternative、Repetitionを継承します。
-Visitor/巡回処理これらのクラスは内部的にSequence、Alternative、Repetitionを継承します。
visit(Sequence)、visit(Alternative)、visit(Repetition)を実装したVisitorクラス。
-Visitor/一連の処理
巡回処理を定義したクラスを継承したVisitorクラス。
visit(document)やvisit(element)を実装します。
visit(document)やvisit(element)を実装します。
Sample に共通する処理の流れ
Sampleを紹介するに当たって、共通となる処理について先に説明します。■共通処理1.トークンリストの作成
構文解析器のサンプルを作成するにあたって、字句解析器部分の処理は実装せず、代わりに字句解析器が返すはずのトークンのリストを手作業で作成します。
トークンリストの作成は、Visitorのコンストラクタで行います。
■共通処理2.処理の開始点とEBNFツリーの作成トークンリストの作成は、Visitorのコンストラクタで行います。
処理の開始点は、AnalyzeSyntaxのmain()とします。
AnalyzeSyntaxのmain()の中でEBNFデータツリーとVisitorを作成し、巡回を行います。
AnalyzeSyntaxのmain()の中でEBNFデータツリーとVisitorを作成し、巡回を行います。

■共通クラス EbnfNodeAcceptor
EbnfNodeAcceptorはVisitorパターンを受け入れるノード側のインタフェースクラスです。実装は次のようになります。
■共通クラス EbnfVisitor
public interface EbnfNodeAcceptor
{
public abstract void accept(EbnfVisitor v);
}
EbnfVisitorはVisitorパターンのVisitorを表すクラスです。
public abstract class EbnfVisitor
{
//終端の処理の書き忘れを防ぐためにEbnfAcceptorはvisitできない
//ようにする
//public abstract void visit(EbnfAcceptor n);
public abstract void visit(EbnfSequenceNode n);
public abstract void visit(EbnfAlternativeNode n);
public abstract void visit(EbnfRepetitionNode n);
・・・・
//以下、個別に処理したいノードが増えたらEbnfXXXNode個別の処理を書く
}
Sample1 単項のLITERAL構文を解析する
単純な単項の構文を解析します。構文は、
EBNFデータツリー:LITERAL ('1.1')
とし、これに対し、
入力トークンリスト:LITERAL ('1.1')
を解析する処理を考えてみます。
共通の処理で説明した内容に加えて、
Sample1Visitor::visit(EbnfLimitedLiteralNode n)
では、トークンの種別をチェックしたあと、内容が一致するか判定します。
■Sample1のAnalyzeSyntax
pulic class AnalyzeSyntax
{
public static void main(String args[])
{
//EBNFデータツリーを作成する
//Literalトークンの中でかつ1.1とだけマッチングOKとなるノード
EbnfLimitedLiteralNode node = new EbnfLimitedLiteralNode("1.1");
//Visitorを作成する
// コンストラクタ内でトークンリストを作成する
Sample1Visitor v = new Sample1Visitor();
//EBNFデータツリーをを巡回する
node.accept(v);
//結果を表示する
System.out.println(v.getResult());
}
}
public class EbnfLimitedLiteralNode implements EbnfNodeAccepter
{
private final String m_matchText;
public EbnfLimitedLiteralNode(String text)
{
m_matchText = text;
}
public boolean equals(String text)
{
return m_matchText.equals(text);
}
public void accept(EbnfVisitor v)
{
v.visit(this);
}
}
public class Sample1Visitor extends EbnfVisitor
{
private boolean m_result;
private ArrayList<Token> m_list;
public Sample1Visitor()
{
//字句解析がまだないので、入力トークン列を作成する。
m_list = new ArrayList<Token>();
LiteralToken token = new LiteralToken("1.1", 0, 3);
m_list.add(token);
}
public boolean getResult()
{
return m_result;
}
@Override
public void visit(EbnfLimitedLiteralNode n)
{
Token token = m_list.get(0);
if(token instanceof LiteralToken)
{
LiteralToken ltoken = (LiteralToken)token;
m_result = n.equals(ltoken.getString());
}
else
{
m_result = false;
}
}
}
Sample2 Sequence構文を解析する
EBNFの生成規則の内、連接を表現するためにEBNFデータツリーのSequence構文を解析します。Sequence構文の確認する内容は、「全ての子ノードを順に処理する」ことです。
より詳細に説明すれば、
子ノードの構文の処理結果を確認する
処理結果がOKの場合は、次の子ノード処理へ
処理結果がNGの場合は、次の子ノード処理へ行かずにSequenceの結果もNGとする
となります。
構文は、
EBNFデータツリー:
seq(Sequence)
├+WORD ('version')
├+SYMBOL ('=')
└+LITERAL ('1.1')
とし、これに対し、
入力トークンリスト:WORD ('version') SYMBOL ('=') LITERAL ('1.1')
を解析する処理を考えてみます。
共通の処理で説明した内容に加えて、
Sample1Visitor::visit(EbnfSequenceNode n)
では、先ほど述べたSequence構文の処理を実装します。また、
Sample2Visitor::visit(EbnfSymbolNode n)
Sample2Visitor::visit(EbnfLimitedWordNode n)
の中でトークンの種別をチェックしたあと内容が一致するか判定します。
■Sample2のanalyzeSyntax
pulic class AnalyzeSyntax
{
public static void main(String args[])
{
Sample2Visitor v = new Sample2Visitor();
//EBNFデータツリーを構築する
EbnfLimitedWordNode version = new EbnfLimitedWordNode("version");
EbnfSymbolNode eq = new EbnfSymbolNode("=");
EbnfLimitedLiteralNode num = new EbnfLimitedLiteralNode("1.1");
EbnfSequenceNode seq = new EbnfSequenceNode();
seq.addChild(version);
seq.addChild(eq);
seq.addChild(num);
seq.accept(v);
System.out.println(v.getResult());
}
}
public class EbnfSequenceNode implements EbnfNodeAccepter
{
private ArrayList<EbnfNodeAccepter> m_children;
public EbnfSequenceNode()
{
m_children = new ArrayList<EbnfNodeAccepter>();
}
public void addChild(EbnfNodeAccepter child)
{
m_children.add(child);
}
public ArrayList<EbnfNodeAccepter> getChildren()
{
return m_children;
}
public void accept(EbnfVisitor v)
{
v.visit(this);
}
}
public class EbnfLimitedWordNode implements EbnfNodeAcceptor
{
private final Pattern m_pattern;
public EbnfLimitedWordNode(String regex)
{
m_pattern = Pattern.compile(regex);
}
public boolean equals(String text)
{
Matcher m = m_pattern.matcher(text);
return m.matches();
}
public void accept(EbnfVisitor v)
{
v.visit(this);
}
}
public class EbnfSymbolNode implements EbnfNodeAcceptor
{
private final String m_matchText;
public EbnfSymbolNode(String text)
{
m_matchText = text;
}
public boolean equals(String text)
{
return m_matchText.equals(text);
}
public void accept(EbnfVisitor v)
{
v.visit(this);
}
}
public class Sample2Visitor extends EbnfVisitor
{
private boolean m_result;
private int m_index;
private ArrayList<Token> m_list;
public Sample2Visitor()
{
m_result = true;
m_index = 0;
//字句解析で取得したトークン列の構成
m_list = new ArrayList<Token>();
WordToken token1 = new WordToken("version", 0, 7);
SymbolToken token2 = new SymbolToken("=", 7, 1);
LiteralToken token3 = new LiteralToken("1.1", 8, 3);
m_list.add(token1);
m_list.add(token2);
m_list.add(token3);
}
public void visit(EbnfSymbolNode n)
{
Token token = m_list.get(m_index);
if(token instanceof SymbolToken)
{
SymbolToken stoken = (SymbolToken)token;
m_result = n.equals(stoken.getString());
if (m_result)
{
m_index++;
}
else
{
//何もしない
}
}
else
{
m_result = false;
}
}
public void visit(EbnfLimitedWordNode n)
{
Token token = m_list.get(m_index);
if(token instanceof WordToken)
{
WordToken wtoken = (WordToken)token;
m_result = n.equals(wtoken.getString());
if (m_result)
{
m_index++;
}
else
{
//何もしない
}
}
else
{
m_result = false;
}
}
public void visit(EbnfSequenceNode n)
{
ArrayList<EbnfNodeAccepter> children = n.getChildren();
for(EbnfNodeAccepter child :children)
{
child.accept(this);
//acceptの結果がOKの場合
if (m_result)
{
//何もしない
}
//acceptの結果がNGの場合
else
{
break;
}
}
}
public boolean getResult(){割愛}
public void visit(EbnfLimitedLiteralNode n){割愛}
}
コメント
コメントを投稿する
SpecialPR