第020回_TokenManagerの実装2_notify系の追加
»
前回に引き続きTokenManagerの実装を行います。
4.条件付字句解析を適切に呼び出す機能
条件付字句解析器の各条件による切り替えの呼び出しタイミングを制御するのはVisitor側の責任です。VisitorはTokenManagerに現在の解析進行状況について通知することでタイミングの制御をします。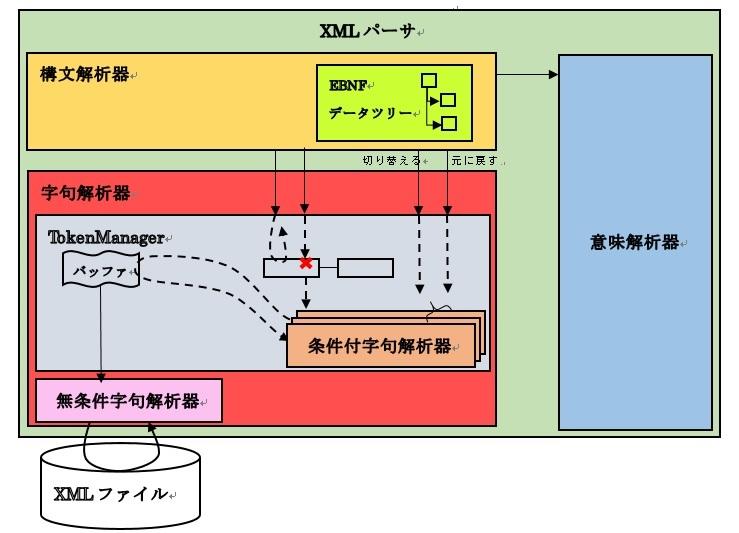
■Visitor側の呼び出し例
Visitor側の実装は次のようになります。
class Visitor
{
・・・・
private static TokenManager m_tokenManager = TokenManager.getInstance();
・・・・
public void visit(EbnfPIWordNode n)
{
//PI_WORDの条件の開始制御
m_tokenManager.notifyPIWordStart();
//この区間でnextToken()を呼び出しときは、
//PI_WORD用の条件付字句解析を呼び出す
Token token = m_tokenManager.nextToken();
m_result = token.match(n);
//PI_WORDの条件の終了制御
m_tokenManager.notifyPIWordEnd();
}
}
例を見てわかる通り、TokenManagerは制御インタフェース
TokenManager.notify$XXXX$Start と TokenManager.notify$XXXX$End
を提供します。
# $XXXX$ 部分は条件名
TokenManager#nextTokenは切り替え指示範囲に応じた適切な条件付字句解析器を呼び出して、範囲の条件に合わせた正しい字句を抽出するものとします。
次に、TokenManagerが提供するnotify$XXXX$Startとnotify$XXXX$Endの処理を考えていきます。
notify$XXXX$Startの処理1
BaseStackLexerの実装
字句解析器のスタックを用意します。
tokenize()の実装
字句解析器を選択する処理を実装したので、前回nextToken()の中で保留していたtokenize()を実装します。
TokenManager.notify$XXXX$Start と TokenManager.notify$XXXX$End
を提供します。
# $XXXX$ 部分は条件名
TokenManager#nextTokenは切り替え指示範囲に応じた適切な条件付字句解析器を呼び出して、範囲の条件に合わせた正しい字句を抽出するものとします。
次に、TokenManagerが提供するnotify$XXXX$Startとnotify$XXXX$Endの処理を考えていきます。
notify$XXXX$Startの処理1
notify$XXXX$Startで解析に必要な字句解析器をTokenManagerに登録します。
登録する字句解析器は
01.CHARDATA_WORDの字句解析器
02.PI_WORDの字句解析器
03.CDATA_WORDの字句解析器
04.IGNORE_WORDの字句解析器
05.AttValue/EntityValueの開始を示すDoubleQouteを解析する字句解析器
06.AttValue/EntityValueの開始を示すQouteを解析する字句解析器
07.AttValueDoubleQuoteSectionの字句解析器
08.AttValueQuoteSectionの字句解析器
09.EntityValueDoubleQuoteSectionの字句解析器
10.EntityValueQuoteSectionの字句解析器
11.NormalSectionの字句解析器
となります。
また、
・EntityRefSection
・CharRefDecimalSection
・CharRefHexSection
・PEReferenceSection
はnotifyは必要ですが、字句解析器はNormalSectionとなります。
字句解析器同士の遷移の構造登録する字句解析器は
01.CHARDATA_WORDの字句解析器
02.PI_WORDの字句解析器
03.CDATA_WORDの字句解析器
04.IGNORE_WORDの字句解析器
05.AttValue/EntityValueの開始を示すDoubleQouteを解析する字句解析器
06.AttValue/EntityValueの開始を示すQouteを解析する字句解析器
07.AttValueDoubleQuoteSectionの字句解析器
08.AttValueQuoteSectionの字句解析器
09.EntityValueDoubleQuoteSectionの字句解析器
10.EntityValueQuoteSectionの字句解析器
11.NormalSectionの字句解析器
となります。
また、
・EntityRefSection
・CharRefDecimalSection
・CharRefHexSection
・PEReferenceSection
はnotifyは必要ですが、字句解析器はNormalSectionとなります。
次に字句解析器の遷移について考えてみます。
notify$XXXX$Startの処理2・1段階の遷移
Aの字句解析器
notify$XXX$Start
→XXXの字句解析器
notify$XXX$End
→Aの字句解析器
・2段階の遷移
AAAの字句解析器
notify$XXX$Start
→XXXの字句解析器
notify$BBB$Start
→BBBの字句解析器
notify$BBB$End
→XXXの字句解析器
notify$XXX$End
→AAAの字句解析器
・3段階の遷移
AAAの字句解析器
notify$XXX$Start
→XXXの字句解析器
notify$BBB$Start
→BBBの字句解析器
notify$YYY$Start
→YYYの字句解析器
notify$YYY$End
→BBBの字句解析器
notify$BBB$End
→XXXの字句解析器
notify$XXX$End
→AAAの字句解析器
トークンバッファに解析中のトークンがある場合のためにトークンバッファは空にリセットします。
notify$XXXX$Endの処理
notify$XXXX$Startで追加した字句解析器をスタックから取り除きます。
またトークンバッファに解析中のトークンがある場合のためにトークンバッファは空にリセットします。
必要なデータまたトークンバッファに解析中のトークンがある場合のためにトークンバッファは空にリセットします。
字句解析器を保存するスタックをフィールドに用意して、コンストラクタで 初期化します。
TokenManagerにnotify系を実装する
public class TokenManager
{
・・・・・
//追加
private BaseStackLexer m_stack;
//シングルトンパターン
private TokenManager()
{
・・・・・
//追加
m_stack = StackLexer.getInstance();
・・・・・
}
//追加
//字句解析器制御メソッド
public void notifyCDataStart()
{
m_stack.pushCData();
m_list.clear();
}
public void notifyCDataEnd()
{
m_stack.pop();
m_list.clear();
}
public void notifyPIWordStart()
{
m_stack.pushPI();
m_list.clear();
}
public void notifyPIWordEnd()
{
m_stack.pop();
m_list.clear();
}
public void notifyCharDataStart()
{
m_stack.pushCharData();
m_list.clear();
}
public void notifyCharDataEnd()
{
m_stack.pop();
m_list.clear();
}
public void notifyIgnoreWordStart()
{
m_stack.pushIgnore();
m_list.clear();
}
public void notifyIgnoreWordEnd()
{
m_stack.pop();
m_list.clear();
}
public void notifyQuoteStart()
{
m_stack.pushQuote();
m_list.clear();
}
public void notifyQuoteEnd()
{
m_stack.pop();
m_list.clear();
}
public void notifyDoubleQuoteStart()
{
m_stack.pushDoubleQuote();
m_list.clear();
}
public void notifyDoubleQuoteEnd()
{
m_stack.pop();
m_list.clear();
}
public void notifyAttValueQuoteSectionStart()
{
m_stack.pushAttValueQuoteSection();
m_list.clear();
}
public void notifyAttValueQuoteSectionEnd()
{
m_stack.pop();
m_list.clear();
}
public void notifyAttValueDoubleQuoteSectionStart()
{
m_stack.pushAttValueDoubleQuoteSection();
m_list.clear();
}
public void notifyAttValueDoubleQuoteSectionEnd()
{
m_stack.pop();
m_list.clear();
}
public void notifyEntityValueQuoteSectionStart()
{
m_stack.pushEntityValueQuoteSection();
m_list.clear();
}
public void notifyEntityValueQuoteSectionEnd()
{
m_stack.pop();
m_list.clear();
}
public void notifyEntityValueDoubleQuoteSectionStart()
{
m_stack.pushEntityValueDoubleQuoteSection();
m_list.clear();
}
public void notifyEntityValueDoubleQuoteSectionEnd()
{
m_stack.pop();
m_list.clear();
}
public void notifyNormalSectionStart()
{
m_stack.pushNormalSection();
m_list.clear();
}
public void notifyNormalSectionEnd()
{
m_stack.pop();
m_list.clear();
}
・・・・
}
字句解析器のスタックを用意します。
public class BaseStackLexer
{
private final NormalSectionLexer m_normalSectionLexer
= NormalSectionLexer.getInstance();
private final PISectionLexer m_piSectionLexer
= PISectionLexer.getInstance();
private final CharDataLexer m_charDataLexer
= CharDataLexer.getInstance();
private final CDataLexer m_cDataLexer
= CDataLexer.getInstance();
private final IgnoreLexer m_ignoreLexer
= IgnoreLexer.getInstance();
private final ReplacementTextLexer m_replacementTextLexer
= ReplacementTextLexer.getInstance();
private final ReplacementTextLexer2 m_replacementTextLexer2
= ReplacementTextLexer2.getInstance();
private final QuoteLexer m_quoteLexer
= QuoteLexer.getInstance();
private final DoubleQuoteLexer m_doubleQuoteLexer
= DoubleQuoteLexer.getInstance();
private final AttValueQuoteSectionLexer m_attValueQuoteSectionLexer
= AttValueQuoteSectionLexer.getInstance();
private final AttValueDoubleQuoteSectionLexer
m_attValueDoubleQuoteSectionLexer
= AttValueDoubleQuoteSectionLexer.getInstance();
private final EntityValueQuoteSectionLexer
m_geEntityValueQuoteSectionLexer
= GeEntityValueQuoteSectionLexer.getInstance();
private final EntityValueDoubleQuoteSectionLexer
m_geEntityValueDoubleQuoteSectionLexer
= GeEntityValueDoubleQuoteSectionLexer.getInstance();
private Stack<ConditionLexer> m_stack;
//シングルトンパターン
public BaseStackLexer()
{
m_stack = new Stack<ConditionLexer>();
m_stack.push(m_normalSectionLexer);
}
public void pushPI()
{m_stack.push(m_piSectionLexer);}
public void pushCharData()
{m_stack.push(m_charDataLexer);}
public void pushCData()
{m_stack.push(m_cDataLexer);}
public void pushIgnore()
{m_stack.push(m_ignoreLexer);}
public void pushNormal()
{m_stack.push(m_normalSectionLexer);}
public ConditionLexer peek()
{return m_stack.peek();}
public void pop()
{m_stack.pop();}
public void pushQuoteStart()
{m_stack.push(m_quoteLexer);}
public void pushDoubleQuoteStart()
{m_stack.push(m_doubleQuoteLexer);}
public void pushAttValueQuoteSection()
{m_stack.push(m_attValueQuoteSectionLexer);}
public void pushAttValueDoubleQuoteSection()
{m_stack.push(m_attValueDoubleQuoteSectionLexer);}
public void pushEntityValueQuoteSection()
{m_stack.push(m_geEntityValueQuoteSectionLexer);}
public void pushEntityValueDoubleQuoteSection()
{m_stack.push(m_geEntityValueDoubleQuoteSectionLexer);}
}
字句解析器を選択する処理を実装したので、前回nextToken()の中で保留していたtokenize()を実装します。
public class TokenManager
{
・・・・・
//追加で解析してlistを補充する
private void tokenize()
{
ConditionLexer lexer = m_stack.peek();
Token token = lexer.nextToken(m_str);
m_list.add(token);
}
}
コメント
コメントを投稿する
SpecialPR