2009年は、いよいよクラウド時代の幕明けですね。世の中的にも大不況ですから、導入・運用コストを下げることが期待されるクラウドはまさにうってつけではないでしょうか? しかし、インターネットのあちら側にあるシステムのことは、いまいちピンとこないことが多いですね。最近よく聞く「CAP定理」なんてのもそのひとつだと思います。この定理時代は、前からあったものですが、もっともらしいことを言って煙(いや雲か。)に巻かれている気がしませんか。そんな「CAP定理」をOracleの分散データベースである「Oracle RAC」を例に取り説明してみたいと思います。
1. CAP定理のジレンマ
クラウドの特徴のひとつとして、CAP定理が挙げられます。
CAP定理とは、以下の3つを同時には満たせないという定理です。
- C:Consistency(データの一貫性)
データの更新後、ほかからそのデータを参照した場合、必ず更新後のデータが参照できることを保証すること。
- A:Availability (システムの可用性)
どのような状態であっても、データの参照が可能であること。例えば、ロック待ちにならない。
- P:Tolerance to network Partitions (ネットワーク分断への耐性)
データが複数のサーバに分散されており、1つのサーバに障害が発生し、データが破損した場合でも、別サーバのレプリケーションにより、データが参照可能であること。
例えば1台のサーバで動作するデータベースを考えると、上のCAPのうち、CAを満たしているが、Pは満たしておりません。APを満たしていて、Cを満たしていない例としてよく挙げられるのがDNSです。また、CPの例としては、ロックの塊である分散データベースがあげられます。
例を挙げてみましたが、各項目の正確な定義が提示されていないため、いまいちピンとこない定理ですね。
そこで、Oracleのクラスタリング技術である「RAC」のアーキテクチャを説明することにより、「データ一貫性」、「パフォーマンス」、「障害復旧性」の観点からCAP定理を理解したいと思います。
いきなり、「Oracle RAC」に入る前に基盤技術となる「データベースアーキテクチャ」から説明したいと思います。
2. データベースアーキテクチャ
この章では1台のサーバで動作するOracleデータベースのアーキテクチャを説明します。
※尚、あくまでCAP定理の説明が目的ですので、データベースのアーキテクチャとしては、実際より簡略化して説明しております。 Oracleアーキテクチャーの詳細が知りたい方は、後述の参考資料を参照ください。
コンピュータの3大要素「中央演算処理装置(CPU)」「記憶装置(Memory)」「入出力装置(HDD)」と同じようにデータベースでも以下の「データベースの3大要素」が重要です。
- プロセス (CPU)
- 共有メモリ(Memory)
- データファイル&ログファイル (HDD)
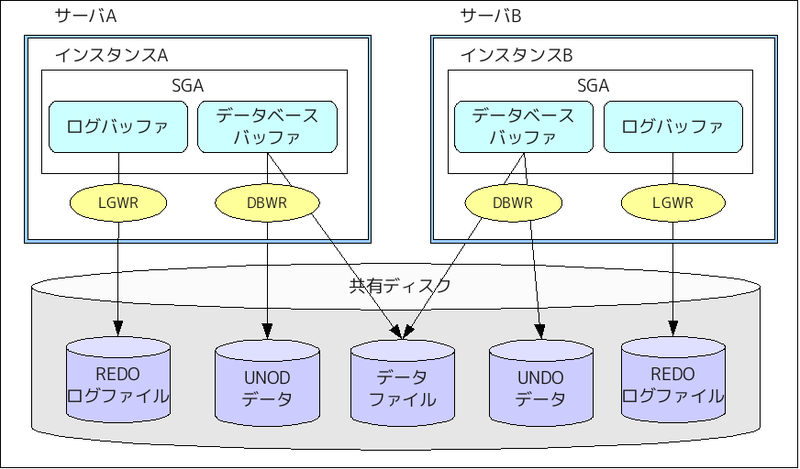
以下にOracleアーキテクチャを図示します。

※1:Oracle インスタンス:プロセス(DBWR、LGWR)と共有メモリの集合体です。
※2:SGA(システムグローバルエリア):データやログ情報を保存するためのメモリ領域です。
※3:DBWR(データベースファイルライター):更新されたデータベースバッファの内容をデータファイルに書き込むプロセスです。
※4:LGWR(ログファイルライター):ログバッファをREDOログファイルに書き込むプロセスです。
最初に、クライアントプログラムからデータを検索する場合の動作を説明します。
◇データ検索時の動作
- クライアントプログラムからSELECT文をサーバプロセスが受け取ります。
- サーバプロセスは、SELECT文を解析し、SGAのデータバッファに要求されたデータが存在するか検索します。
- データバッファに存在しない場合、データファイルからデータを読み込みデータバッファに保持し、クライアントプログラムに返します。
次に、データを更新する場合の動作を説明します。
◇データ更新時の動作
- クライアントプログラムからUPDATE文をサーバプロセスが受け取ります。
- サーバプロセスは、UPDATE文を解析し、SGAのデータバッファに更新対象のデータが存在するか検索します。
- データバッファに存在しない場合、データファイルからデータを読み込みデータバッファに保持し、データバッファ上のデータを更新します。同時にデータバッファ上にUNDO情報(更新前のデータ)を保持し、更新後データをロブバッファに保持します。
※この時点では、メモリ上のデータ(データバッファとログバッファ)のみを更新し、ファイルには書き出しません。
- クライアントプログラムからCOMMIT命令をサーバプロセスが受け取ります。
- サーバプロセスは、COMMITのタイミングで、ロブバッファをREDOログファイルに書き込みます。
※この時点では、データバッファは、データファイルに書き出しません。データバッファに更新データを貯めて、まとめてデータファイルに書き出します。
- データがCOMMITされたことをクライアントプログラムに通知します。
データ更新時の動作は、検索時の動作と比べて複雑です。なぜでしょうか?
データベースに必須とされる3大原則を満たすためです。
◇「データベースの3大原則」
2-1. パフォーマンス
データベースは、パフォーマンスが命です。大量データの読み込み、書き込みを速くするためには、やはり、3つのポイントがあります。
◇「パフォーマンスの3大原理」
- メモリの活用
- まとめて処理
- 用途別のアクセス方法
◇メモリの活用
HDDよりもメモリにアクセスする方が何百万倍も高速です。頻繁に使うデータをメモリ上に配置することをキュッシュするといいます。このキャッシュのアルゴリズムがパフォーマンスの鍵となり、またサイズ設定等が重要なチューニングポイントとなります。このため、クライアントプログラムから検索や更新の要求がきた場合、サーバプロセスは、データをメモリにキャッシュします。
◇まとめて処理
コンピュータの仕組みとして、細かい処理を複数実行するよりも、まとめて実行した方が効率がよくなります。そのためデータを更新する場合、まずメモリ上のデータを更新し、HDD上のデータはまだ更新しません。ある程度の量がたまった段階でHDDに書き込みます。データ更新時にHDDに書き込むとI/O待ちでパフォーマンスが低下するためです。このことを遅延書き込みといいます。
◇用途別のアクセス方法
SGA上にデータバッファとログバッファの2種類が存在しますが、それぞれ、データファイルとREDOログファイルに対応付けられます。そして、データファイルはランダムアクセスを行う必要がありますが、REDOログファイルはシーケンシャルアクセスで済むという特徴があります。
ファイル全体を不規則に読み込み、書き込みを行う操作のことを言います。データファイルの場合、該当データがデータファイルのいろいろな箇所に存在するため、不規則にファイルを読み込む必要があります。ファイルを保存するHDDは、円盤の磁気ディスクを物理的にアームが動いて読み取る必要があるため、不規則な読み込みを行うとアームを動かすための時間がかかります。
ファイルの頭から最後尾に向かっての順次読み込みや、最後尾への順次書き込みの操作をいいます。この場合、アームは順次に動けば良いのでアクセスはランダムアクセスに比べて高速です。
このランダムアクセスとシーケンシャルアクセスの特徴をふまえて、データファイルとREDOログファイルを別々のHDDに配置するのが、良い物理設計となります。また、データファイルは複数のHDDに配置し、I/Oを分散させることでパフォーマンスの向上を狙います。ハードウェア的には、データファイルを配置する箇所は「RAID 10構成※1」とし、ログファイルを配置する箇所は「RAID 1(ミラーリング)」とするのがよく行われます。
※1:RAID 10:RAID 1のミラーリングとRAID 0のストライピングを合わせた構成です。
2-2. データの一貫性
いくらパフォーマンスが速かったとしても、データの一貫性が保証されいなければ、意味がありません。データベースはトランザクション管理を行うことにより、データの一貫性を保証します。トランザクション管理には、「ACID」と呼ばれる機能が必要となります。「ACID」とは、以下の4つの機能の頭文字を取ったものです。
- Atomicity(原子性)
トランザクションに含まれる処理が全て実行されるか、または全く実行されないことを保証する機能です。
- Consistency(一貫性)
トランザクション開始と終了時にあらかじめ与えられた一貫性を満たすことを保証する機能です。
- Isolation(独立性)
トランザクション中に行われる操作の過程が他の操作から隠蔽されることを保証する機能です。トランザクション途中のデータが他トランザクションから参照されないようにします。
- Durability(データの永続化)
トランザクション操作が完了したタイミングで、その操作が永続的となり、結果が失われないことを保証する機能です。
クラウド環境では、今回説明するCAP定理により、システム全体としてACIDを完全に満たすことは難しいため、BASEという考え方でシステム設計を行います。またこの中で、Eventually Consistencyという考え方が提案されております。このACIDとBASEについては、別記事にて説明します。ここではACIDについて概略だけ述べます。簡単にいうと、トランザクション処理で、処理開始前と開始後でデータの一貫性が保証されており、トランザクション処理途中のデータは、ほかのトランザクションから参照できないようにすることです。Oracle では、COMMIT時にログバッファを必ず、REDOログファイルに同期させることと、データバッファ上のデータ更新時にUNDO情報を作成することにより実現しております。
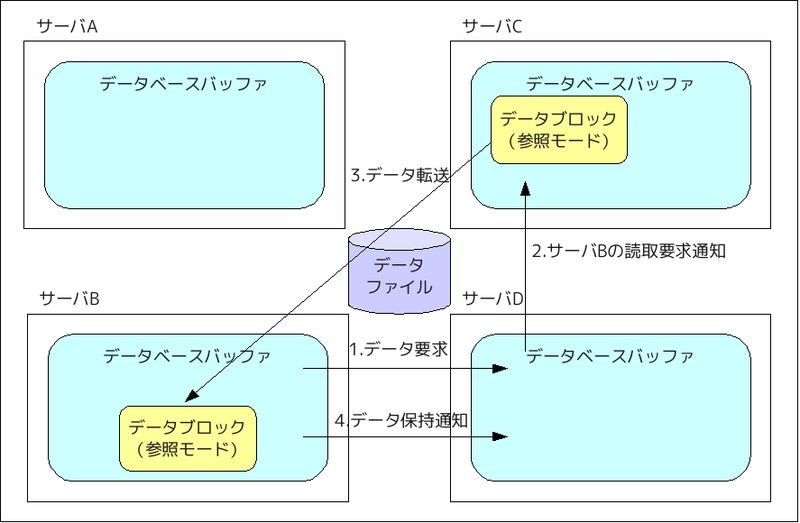
◇トランザクション処理と読み取り一貫性
以下に、トランザクション処理と読み取り一貫性を図示します。

2-3. 障害復旧性
ACIDのDurability(データの永続化)を満たすためには、COMMITされたデータは、例え直後に障害が発生したとしても、復旧できる仕組みが必要となります。Oracleでは、I/O負荷を下げるためにデータファイルの遅延書き込みを行いますが、メモリ上のデータバッファが、まだデータファイルに書かれていない時にサーバがダウンした場合、どうなるでしょうか?
COMMIT時にREDOログファイルが書かれていることが保証されているため、REDOログファイルが破損しない限り、復旧可能となります。REDOログファイルは非常に重要なため、必ず二重化を行います。
]]>















{kind=link}
{kind=link}
{kind=link}
{kind=link}