こんにちは、hiroshiです。今日は、半定常作業の「MySQL増設作業」について書こうと思います。
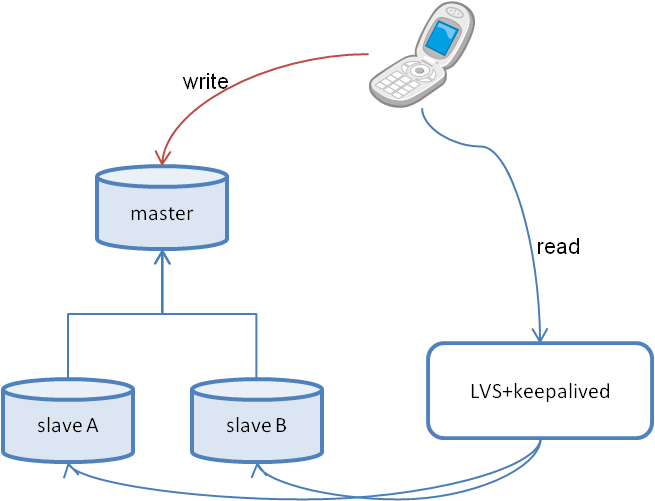
下図のように、master1台←slave2台がLVS+keepalivedで負荷分散構成されているDBがあるとします。
図1.master-slave構成
この構成の組み方にしようかと思ったのですが、これはググったらいっぱいあったので、ホッテントリは狙えないと思ってやめました。
なので、今回のテーマは「このテーブルはwriteは余裕だけどreadがきつくなってきたから、slaveを増設しなければ!」となった場合のslaveを増設する手順について書いてみます。
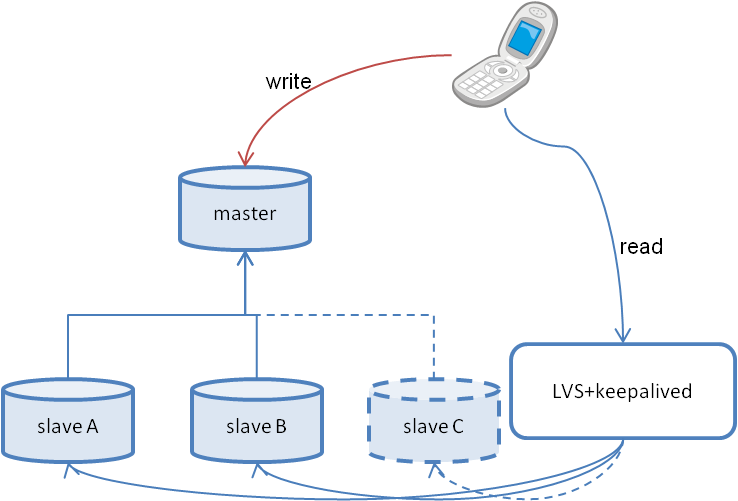
下図のslaveCを追加するぞ! の場合です。
図2. slave Cを追加するぞ
※今回はengine=innoDBの前提で書きます。
※各種userとかIPとかその辺はそこそこ適当に書いてます。
大まかな手順は以下です。
- コピー元となるslaveを1台LVSから切り離す
- slave→masterのreplicationを止める
- dumpを取る
- dumpファイルを移動させる
- dumpファイルをインポートする
- LVSに参加させる
こんな感じです。
1. コピー元となるslaveを1台LVSから切り離す
忙しいDBでいきなり切り離すと、sleepのプロセスが大量発生するので、weightを1にしてから外すことにしています。
keepalived.conf
# slave A
real_server 192.168.0.101 3306 {
weight 1 ←1にする。(通常10にしてます)
inhibit_on_failure
TCP_CHECK {
connect_port 3306
connect_timeout 3
}
}
# slave B
real_server 192.168.0.100 3306 {
weight 10
inhibit_on_failure
TCP_CHECK {
connect_port 3306
connect_timeout 3
}
}
weight1にして
svc -h /servie/keepalive
# slave A
#real_server 192.168.0.101 3306 {
# weight 1 ←1にする。(通常10にしてます)
# inhibit_on_failure
# TCP_CHECK {
# connect_port 3306
# connect_timeout 3
# }
#}
# slave B
real_server 192.168.0.100 3306 {
weight 10
inhibit_on_failure
TCP_CHECK {
connect_port 3306
connect_timeout 3
}
}
コメントアウトして
svc -h /servie/keepalive
LVSからの切り離しは完了です。
2. slave→masterのreplicationを止める
slave A上のmysqlでshow processlistするなどして、アクセスされなくなったのをやわらかく確認します。
小心者のぼくは、最終的にはtcpdumpとかでmysqlのパケットが流れてこないかを確認するのですが、この時点ではまだreplicationしたままなのでバリバリmysqlのパケットが流れています。
mysql> show slave status\G
~中略~
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
1 row in set (0.00 sec)
mysql> stop slave;
~中略~
Master_Host: master
Master_User: hoge
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000049
Read_Master_Log_Pos: 760141636
~中略~
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
1 row in set (0.00 sec)
ということで、この時点でreplicationが止まりました。
Seconds_Behind_Master: NULL
がreplicationが止まった合図です。で、
Master_Log_File: mysql-bin.000049
Read_Master_Log_Pos: 760141636
これからdumpをとるのですが、そのデータはmasterのbinログファイルが「mysql-bin.000049」で、そのファイルの位置が「760141636」の状態のものだという意味です。]
部分的なコピペでもいいんですが、だいたいこんな感じshow slave status自体をファイルに落としておいておくといいかもです。
mysql> \T slave_status.txt
mysql> show slave status \G
mysql> \t
で、ここでtcpdump -i eth0 port 3306とかやってパケットが流れないのを確認すると、精神衛生上いいので僕はそうしてます。
3. dumpを取る。
容量のでかいDBの場合、dumpに半日以上かかることもざらなので、screenを使います。screenじゃなくてもnohup使うでもなんでもいいんですが、不慮のネットワーク切断に備えた何かをやっておいた方が賢明です。
$ screen
$ mysqldump -u root -p database_stage > dump_database_stage.sql
$ mysqldump -u root -p database_release > dump_database_release.sql
※テスト環境用のDBもあるので、一緒にダンプします。
これでひたすら待ちます。ZABBIXのロードアベレージとかがグイーンと上がるので、それが下がったら「終わったかな」と思って見にいきます。dumpが終わったら通知メールを送るようなスクリプトを書いてもいいんですが、必要に思ったことがないので今はそういうのはないです。
ちなみに、だいたいの場合において、このdumpをとっているスキに増設先のmysqlの構築を済ませておきます。
dumpが終わったらreplicationを再開させます。
mysql> start slave;
replicationをとめてた時間などにもよりますが、
mysql> show slave status\G
~中略~
Seconds_Behind_Master: 1348615
と、こんな感じになっているので、0になるのを待ちます。これも見つめていてもなかなか終わらないので、ZABBIXを利用します。Seconds_Behind_Masterの値は、常時監視項目としてZABBIXで監視+閾値でアラートを設定しているので、これを利用してreplicationが追いつくタイミングを知ることもできます。
ここでちょっとワンポイントなのですが、replicationが追いついた後、
mysql> select count(*) from table;
をします。
innodb限定の手順なのですが、これでinnodb_buffer_poolにデータを乗せようとしています。これをやらないでいきなりユーザーからのアクセスにさらすと、処理がおっつかずにreplicationのディレイが発生しちゃったりします。
ところで、上述のとおり、slave増設はslave1台をサービスから切り離してdumpを取る、という作業手順になります。
ですが、増設のきっかけは「負荷が厳しいから」だけではなくて「slaveが1台故障したから」というケースもあります。
故障のケースでmaster1台←slave2台の構成だと、故障後はmaster1台←slave1台という構成と同義になり、そこからslaveを切り離してしまうとサービスに利用できるslaveがなくなってしまいます。最悪負荷の低い深夜帯に、masterにreadも担当させてやるか、サービスを止めるかなどするしかなくなってしまうので、そこそこ途方にくれます。
ですので、slaveは3台が基本です。
※masterがblackholeの場合を考慮すると「実体のあるDB3台が基本」という言い方もあります。
このことはid:naoyaさんの著書「大規模サービス技術入門」にも書いてあったのですが、僕たちは、実際に途方にくれた後にこの著書に出会い、「もっと早くこの本に出会えていれば」と悔やみました。
4. dumpファイルを移動させる。
sftpでもscpでもいいです。増設先のサーバに移動させるだけです。
ただ、うちではサーバ間のinとoutのトラフィックをZABBIXで監視してます。で、特に何もしないとscpでも全力でファイル転送されるため、監視の閾値を超えてしまい、アラートメールが飛んできてしまいます。
そうすると、周りに冷たい目で見られるので,
ZABBIXのトラフィック監視をOffにしておくことを忘れてはいけません。
この移動もファイルの容量次第ではscreenするなりしておきます。
5. dumpファイルをインポートする
$ mysql -u root -p database_stage < dump_database_stage.sql
$ mysql -u root -p database_release < dump_database_release.sql
これも相当時間がかかるケースがあるので、screenなりをしておきましょう。 インポートが終わったら、replication設定をします。
mysql> change master to master_host='マスターホスト名', master_user='repl', master_password='repl', master_log_file='ログファイル名', master_log_pos=ポジション;
この「ログファイル名」と「ポジション」に2でメモったMaster_Log_FileとRead_Master_Log_Posを入れます。 その後は
mysql> start slave;
して、Seconds_Behind_Masterが0になるのを待ってselect count(*)やっての手順は先ほどまでと同じです。
6. LVSに参加させる
これで最後です。 keepalived.conf
# slave A
real_server 192.168.0.101 3306 {
weight 10
inhibit_on_failure
TCP_CHECK {
connect_port 3306
connect_timeout 3
}
}
# slave B
real_server 192.168.0.100 3306 {
weight 10
inhibit_on_failure
TCP_CHECK {
connect_port 3306
connect_timeout 3
}
}
# slave C
real_server 192.168.0.99 3306 {
weight 1 ←1からはじめる
inhibit_on_failure
TCP_CHECK {
connect_port 3306
connect_timeout 3
}
}
新しく追加したDBのweightは1からはじめます。何かしくじってたときのダメージを低くするためです。アプリのエラーログを監視しながらこの作業は行い、エラーがでれば即戻します。各種グラフを見ながらweightを10にまで持っていけたら作業完了です。 以上が単純なslaveの増設方法です。
これ、役に立つと思うので、ぜひ試してみてください。
では、また会いましょう。
]]>