第022回_字句解析の共通クラス1_ConditionLexer
»
前回まででTokenManagerの整理が完了したので今回から条件付字句解析器を検討します。
今回は、字句解析器の中のクラスが共通で利用する トークンクラス、CoditionLexerクラス、TermTokenizerクラスを用意します。
実装は割愛します。
今回は、字句解析器の中のクラスが共通で利用する トークンクラス、CoditionLexerクラス、TermTokenizerクラスを用意します。
トークンクラス
生成するトークンに準正常系などを加えたトークンを用意します。+部分は継承関係を示します。| クラス名 | 説明 | |
| ―――――――――――――――――――――――――――――――――――――――― | ||
| Token | 全てのトークンの親クラス(文字列とログ出力のためにトークン位置を保持します) | |
| +DocumentToken | ファイルからRistrictCharを除いたクラス | |
| +NonDocumentToken | 字句解析器を通して生成するクラス | |
| +CharDataToken | CHARDATA_WORDを示すクラス | |
| +CDataToken | CDATA_WORDを示すクラス | |
| +IgnoreWordToken | IGNORE_WORDを示すクラス | |
| +PIWordToken | PI_WORDを示すクラス | |
| +NormalTokenA1Token | NORMAL_TOKEN_A1を示すクラス | |
| +NormalTokenA2Token | NORMAL_TOKEN_A2を示すクラス | |
| +NormalTokenB1Token | NORMAL_TOKEN_B1を示すクラス | |
| +NormalTokenB2Token | NORMAL_TOKEN_B2を示すクラス | |
| +CommentToken | COMMENT_TOKENを示すクラス | |
| +SymbolToken | SYMBOLを示すクラス | |
| +WhiteSpaceToken | WHITE_SPACEを示すクラス | |
| +WordToken | WORDを示すクラス | |
| +LiteralToken | LITERALを示すクラス | |
| +EofToken | ファイルの終端(EOF)を示すクラス | |
| +UnknownToken | 字句解析器で取りえない文字列を扱うためのクラス | |
| +BadCommentToken | COMMENT_TOKENで正しくコメントの終りがない場合のクラス | |
条件付字句解析器に共通の内容-ConditionLexer
条件付字句解析器に共通の内容について説明します。
■ConditionLexerの数
立ち位置を図示すると次のようになります。
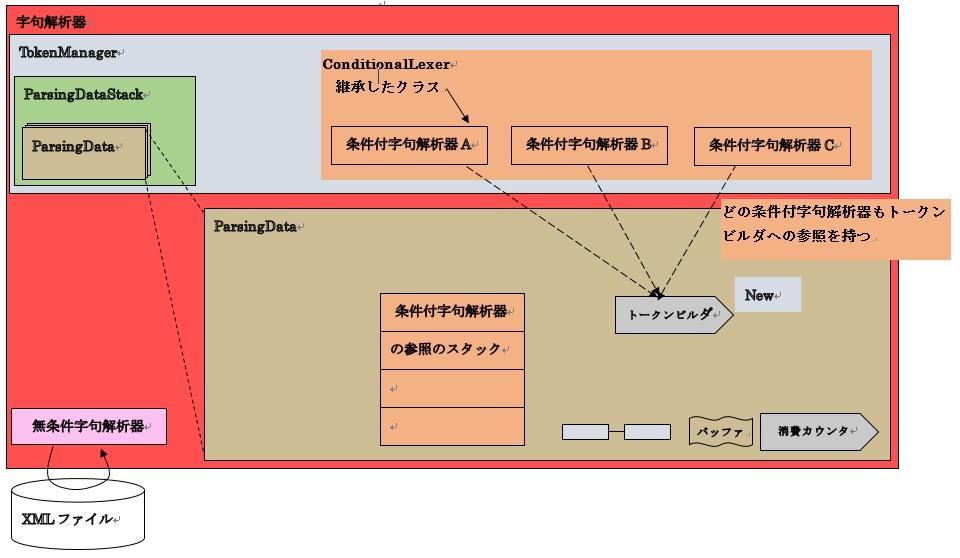
22-1.ソフトウェア構成図
オブザーバーパターンによるTokenBuilderの参照を更新する流れは次のようになります。
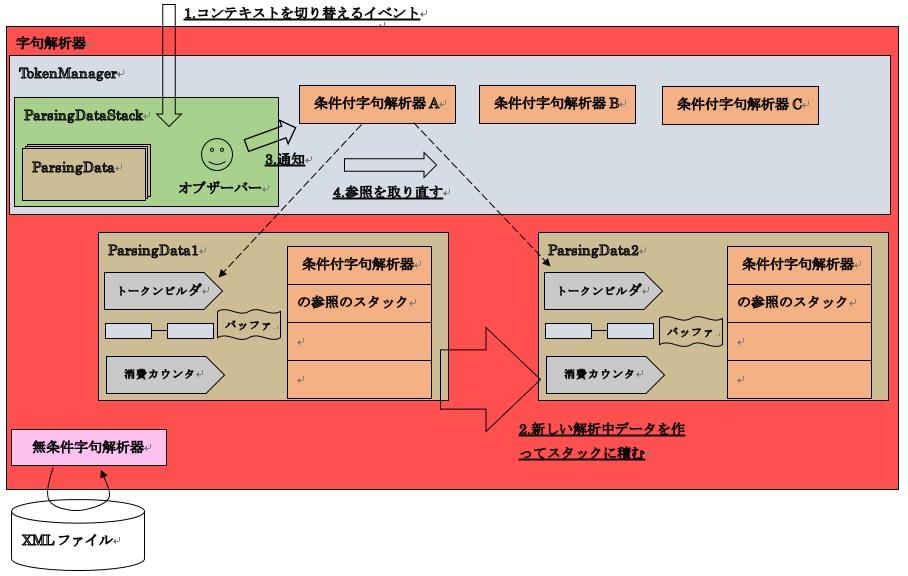
22-2.TokenBuilderの参照を更新する流れ
■実装
■ConditionLexerの数
ConditionLexerは抽象クラスなのでインスタンスの数については定義しません。
■TokenManagerがStackLexerを通じて呼び出すメソッド
条件付字句解析器は、StackLexer上でStackとして管理します。また、StackLexerはConditionLexer#nextToken を呼び出すこととします。つまり、ConditionLexerは抽象メソッドnextTokenを実装します。
■解析データに対する解析深度は深度1とする
字句解析器が複雑化する1つの要因は、大量のif文やswitch文によって処理が分岐しすぎる点(複雑になりすぎる点)です。対策として、条件付字句解析器(CondtionLexerクラス)が担当する部分を
1文字目を解析してトークンが確定しない場合、
トークン作成器(TermTokenizerクラス)に処理を委譲する
と決めます。これを解析深度1とこのコラムでは呼びます。この設計思想は、
多くのトークンが最初の1文字でどのトークンになるかが決まること
と
最初の1文字で複数のトークン候補があったとしても
ある程度のグループ化ができること
を勘案すると複雑化を抑えることができ概ね妥当と言えます。
■TokenBuilderフィールド1文字目を解析してトークンが確定しない場合、
トークン作成器(TermTokenizerクラス)に処理を委譲する
と決めます。これを解析深度1とこのコラムでは呼びます。この設計思想は、
多くのトークンが最初の1文字でどのトークンになるかが決まること
と
最初の1文字で複数のトークン候補があったとしても
ある程度のグループ化ができること
を勘案すると複雑化を抑えることができ概ね妥当と言えます。
字句解析中の未完成なトークンはCondtionLexerとTermTokenizerの間を行き来したり、再帰的にクラス内のメソッドを呼び出すこともあるため、トークンを作る機構をTokenBuilderフィールドとして用意します。
ただし、字句解析中のトークンは解析している区間で唯一つであるため、シングルトンの解析中のデータParsingDataにて管理し、ConditionLexer側で参照を保持します。
■オブザーバーパターンただし、字句解析中のトークンは解析している区間で唯一つであるため、シングルトンの解析中のデータParsingDataにて管理し、ConditionLexer側で参照を保持します。
解析中のデータの文脈が切り替わるとき、それまで作成していた(作成中の)TokenBuilderは破棄します。それに合わせて、ConditionLexer側が参照しているTokenBuilderフィールドも参照を更新せねばなりません。
よって、オブザーバーパターンを使って参照の更新が行えるようにします。
■立ち位置よって、オブザーバーパターンを使って参照の更新が行えるようにします。
立ち位置を図示すると次のようになります。

オブザーバーパターンによるTokenBuilderの参照を更新する流れは次のようになります。

■実装
実装は次のようになります。
public abstract class ConditionLexer
implements Observer
{
private static ParsingDataStack m_parsingData
= ParsingDataStack.getInstance();
protected TokenBuilder m_tokenBuilder;
public ConditionLexer()
{
m_parsingData.addObserver(this);
m_tokenBuilder = m_parsingData.getTokenBuilder();
}
public abstract Token nextToken(StringBuilder str);
//オブザーバパターン
public void update()
{
m_tokenBuilder = m_parsingData.getTokenBuilder();
}
}
ParsingDataStackの修正
関連してParsingDataStackを以下のように修正します。
public class ParsingDataStack
{
private ArrayList<Observer> m_observers;
private ParsingDataStack()
{
・・・
//追加
m_observers = new ArrayList<Observer>();
}
public void newContext(String parameterName, StringBuilder newBuffer)
{
・・・
//追加
this.notifyObserver();
}
public void newContext(DocumentToken t)
{
・・・
//追加
this.notifyObserver();
}
//1つ前のコンテキストに戻る
public void goBackPreviousContext()
{
・・・
//追加
//m_tokenBuilderの取り直し
this.notifyObserver();
}
・・・・
//追加
public StringBuilder getStringBuilder()
{
BaseParsingData pd = m_data.peek();
return pd.getStringBuilder();
}
//追加
//オブザーバパターン
public void addObserver(Observer ob)
{
m_observers.add(ob);
}
//追加
private void notifyObserver()
{
for (Observer ob :m_observers)
{
ob.update();
}
}
}
ParsingDataの修正
同じくParsingDataを以下のように修正します。
長くなったので、TokenBuilderとTermTokenizerの解説は次回にします。
public class ParsingData
{
・・・
//追加
private TokenBuilder m_tokenBuilder;
public BaseParsingData(String filePath, StringBuilder newBuffer)
{
・・・
//追加
m_tokenBuilder = new TokenBuilder(filePath);
}
//追加
public TokenBuilder getTokenBuilder()
{
return m_tokenBuilder;
}
・・・・
}